
并发下的Map

并发下的Map
jwangHashMap分析
JDK7的HashMap
HashMap在日常开发中是很常见的,在JDK7中其底层是由数组+链表构成,数组被分成一个个桶(bucket),通过哈希值决定了键值对在这个数组中的位置。哈希值相同的键值对,会以链表形式进行存储。每一个键值对会以一个Entry实例进行封装,内部存在四个属性:key,value,hash值,和用于单向链表的next。
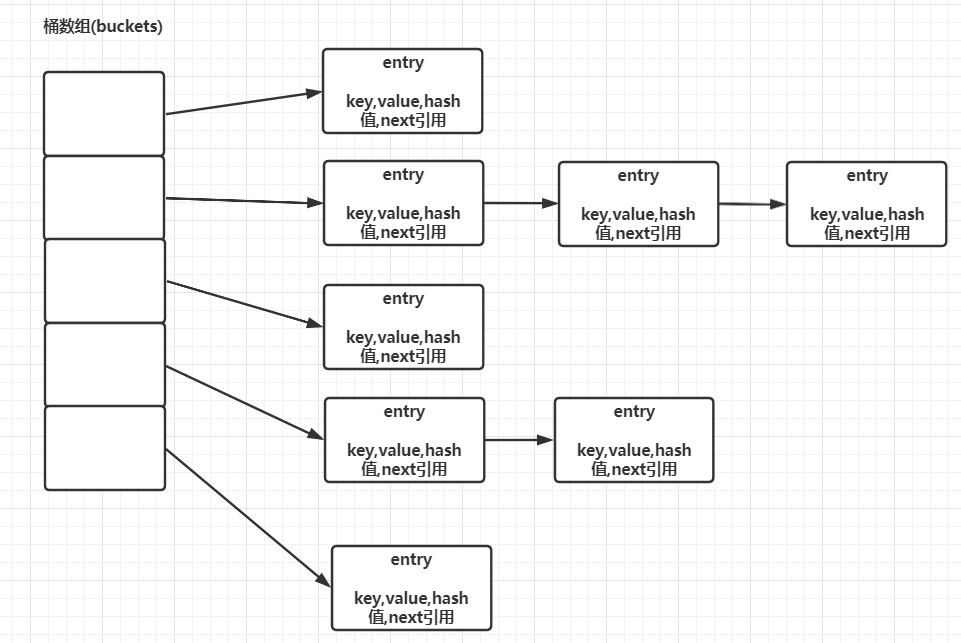
当对HashMap初始化时,其构造函数中需要传入两个参数:initialCapacity、loadFactor

hashMap中还有一个变量:threshold(扩容阈值。计算公式:capacity * load factor)

添加数据过程(put)
- 在第一个元素插入HashMap时做一次数组的初始化,先确定初始的数组大小,并计算数组扩容的阈值。
- 使用key进行Hash值计算,然后通过
(n - 1) & hash判断当前元素存放的位置(这里的 n 指的是数组的长度),用于确定当前键值对要放入哪个Bucket中。 - 找到Bucket后,如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同;如果没有重复,则将此Entry放入链表的头部;如果出现重复,则将此Entry放入链表的尾部,同时建立与前一个节点的连接。
- 在插入新值时,如果当前Buckets数组大小达到了阈值,则触发扩容。扩容后,为原大小的两倍。扩容时会产生一个新的数组替换原来的数组,并将原来数组中的值迁移到新数组中。
JDK7的HashMap扩容流程
API调用过程
1)当调用HashMap的put方法时,其内部会调用addEntry方法添加元素。

2)在addEntry中,如果条件满足则调用resize方法进行扩容。扩展为原大小的两倍。
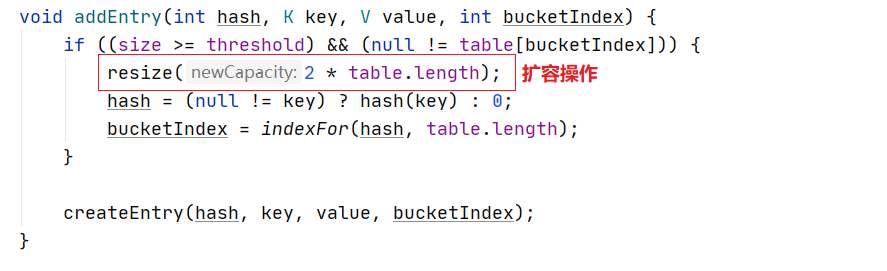
3)在resize方法中,会调用transfer方法根据新的容量去创建新的Entry数组,命名为newTable。

4)在transfer方法中会轮询原table中的每一个Entry重新计算其在新Table上的位置,并以链表形式连接

5)当全部轮询完毕,则在resize方法中将原table替换为新table。

图例分析
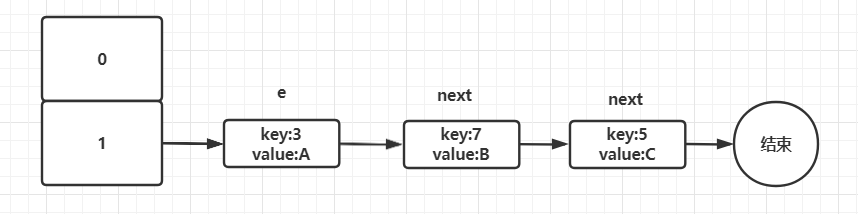
1)假设现在有一个hashMap,buckets数组大小为2,内部存在三个元素。假设现在通过key%buckets长度,则3、5、7%2 都为1,则这三个元素都进入1号中,形成一个链表。
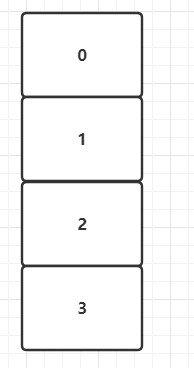
2)当发生扩容时,根据源码会对原数组进行二倍扩容,则现在buckets数组长度为4。
3)当在transfer方法中对原数组中Entry进行遍历时,首先遍历到key为3的元素,此时需要通过3%4=3。所以该Entry会放入三号桶中。
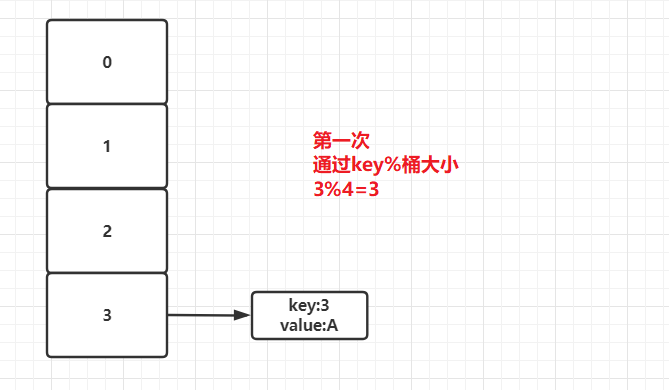
4)接着遍历到key为7的元素,此时取模结果仍为3,则该Entry也会放入三号桶中。但是在HashMap中采用的是头插法,后进来的元素会放在队列的头部。

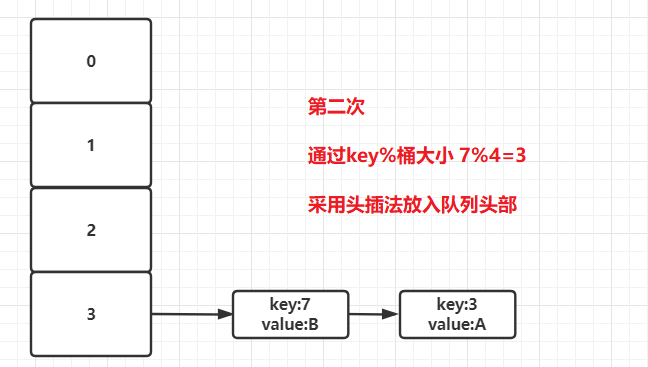
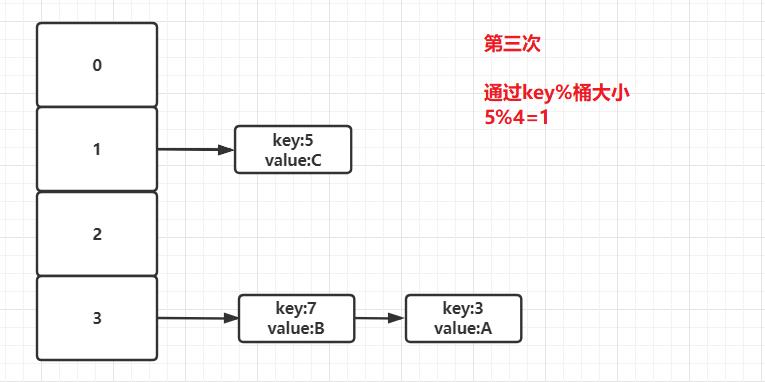
5)接着遍历到key为5的元素,此时取模结果为1,则该Entry放入一号桶中。
JDK7hashMap死循环解析
在JDK8之前,生产环境下的系统经常会出现CPU100%占用,当查看堆栈信息,经常发现程序都卡在了hashMap.get()上,当将系统重启就好了。但是过了一段时间就又会这样,而且在测试环境时又没有问题。后来发现是因为在多线程操作hashMap,当进行rehash时,会造成hashMap出现死循环,原因就在于其内部会形成一个循环链表。 该问题在JDK8之后得以解决,但是仍然不推荐在多线程环境下直接使用HashMap,因为有可能会造成数据丢失,建议使用ConcurrentHashMap。
死循环出现原因分析
void transfer(Entry[] newTable, boolean rehash) { |
单线程下的Rehash
假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]里。效果如下:
此时执行数组扩容,按照扩容规则,buckets数组扩容为原大小的两倍,变为长度为4,接着进行rehash重新计算原数组中元素在新数组中的位置。
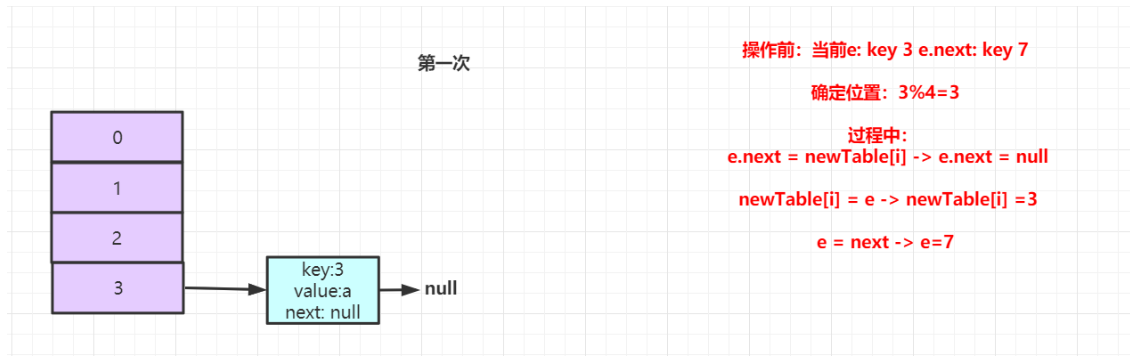
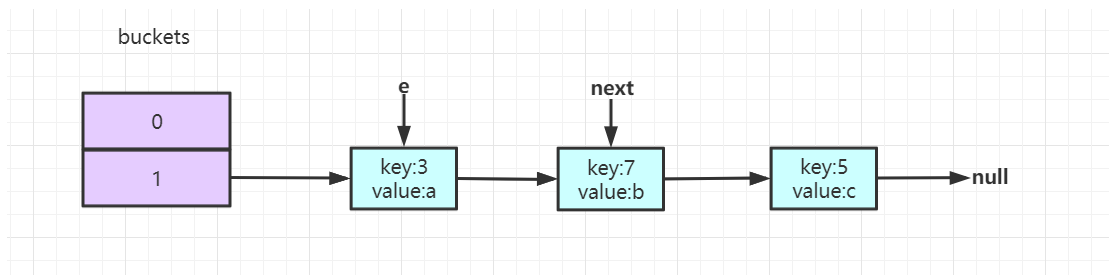
第一次操作完后,key:3 放入到buckets[3]的位置,此时e指向原数组中的7,e.next也为7,结构如下所示:

接着进入到第二次循环,此时e为7,当执行Entry<K,V> next = e.next时,next指向5。接着执行后续逻辑,效果如下所示:
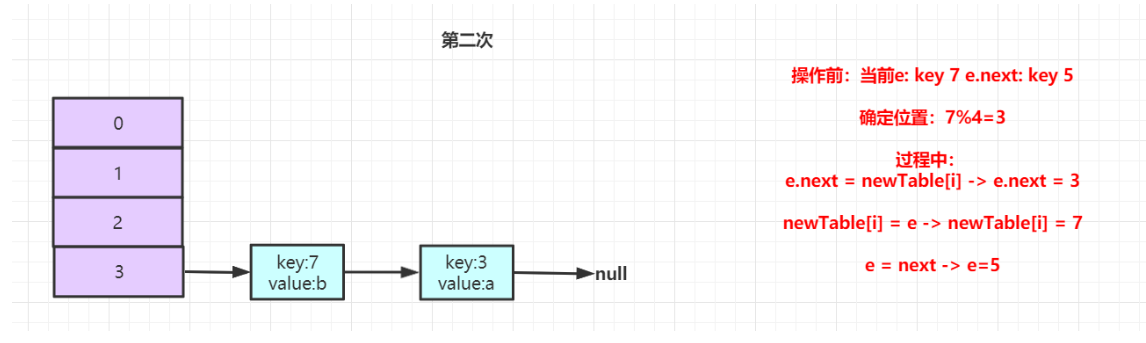
第二次操作完后,key:7放入到buckets[3]的位置,并且处于key:3的前面。继续进行遍历,此时e为5,e.next为null。
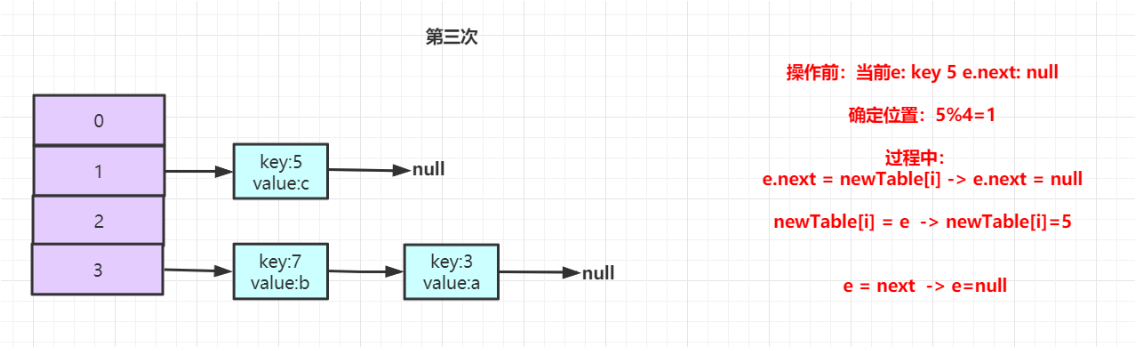
根据当前流程可以发现,当在JDK7中的hashmap采用的是头插法,会将扩容之前的元素顺序进行反转。
并发下的Rehash
假设现在有两个线程,红色为线程一,蓝色为线程二。
扩容前hash结构
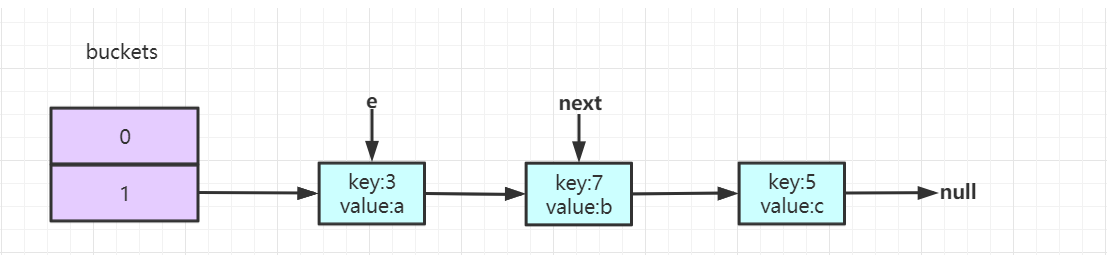
此时两个线程同时执行,因为hashmap不能保证线程安全,所以两个操作的是同一个hashmap空间。当进入到transfer(),在执行完Entry<K,V> next = e.next时,两个线程状态如下所示:
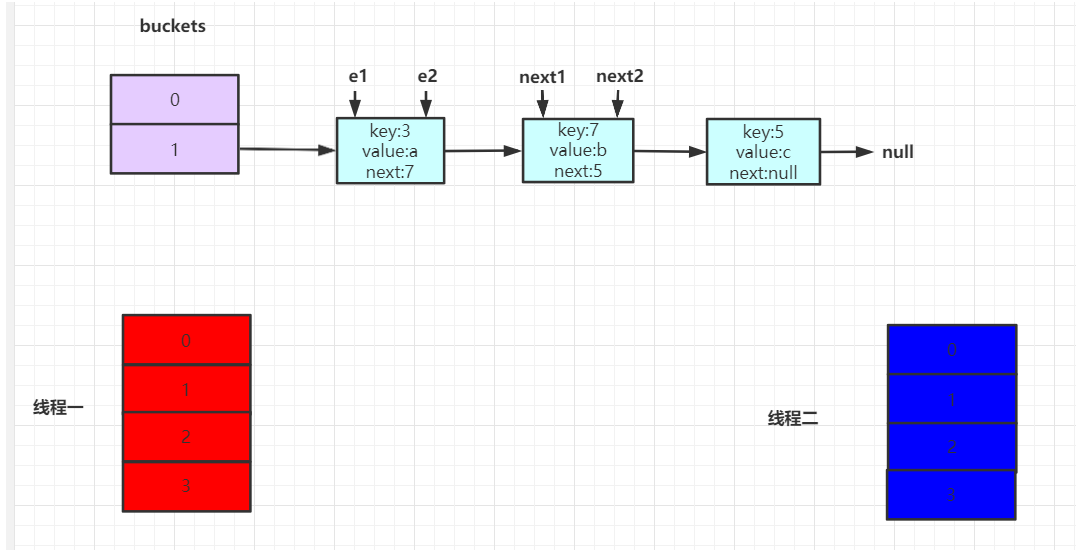
假设线程一在执行到Entry<K,V> next = e.next;时被挂起了,那么此时线程一记录的e为3,e.next为7。结构如下
接着线程二执行,将整个rehash过程执行完毕。执行完毕效果如下:
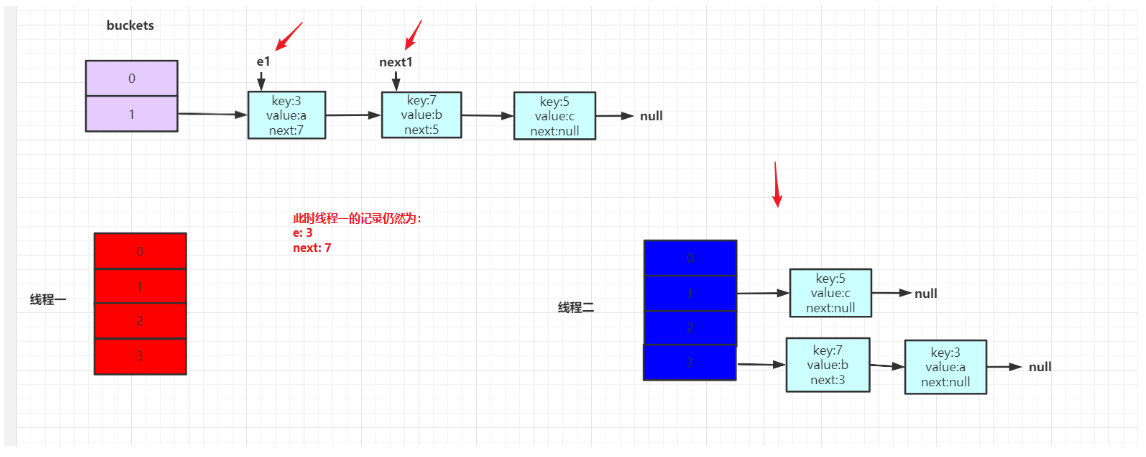
接着线程一开始执行,但是线程一之前的记录为e为key3,e.next为key7。因此继续执行的话,会指向线程二Rehash之后的链表。形成结构如下:
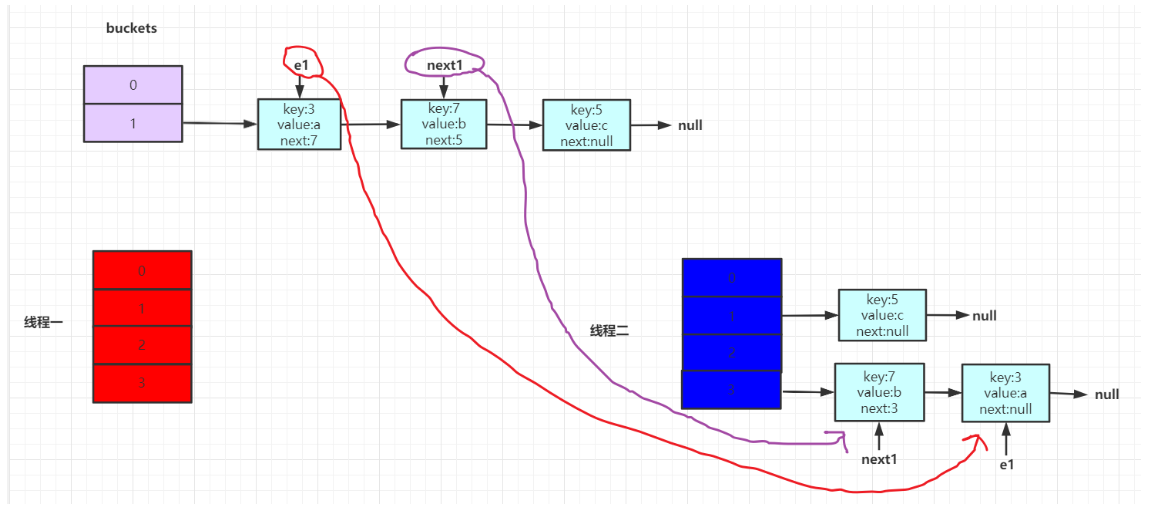
此时可以发现问题,按理说,e应该是在next的前面,但是现在顺序发生问题了。
线程一操作的就是线程二Rehash之后的hashMap
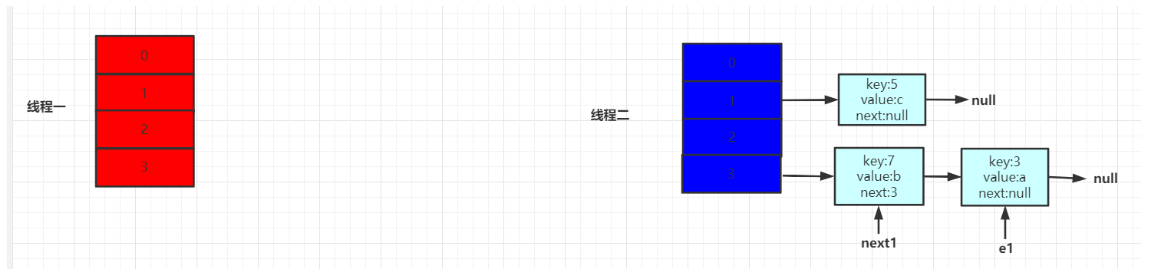
接着线程一继续执行后续代码

当一次循环后,效果如下所示:

接着进行第二次循环。此时e指向7,当执行Entry<K,V> next = e.next时,此时next指向3。效果如下所示:
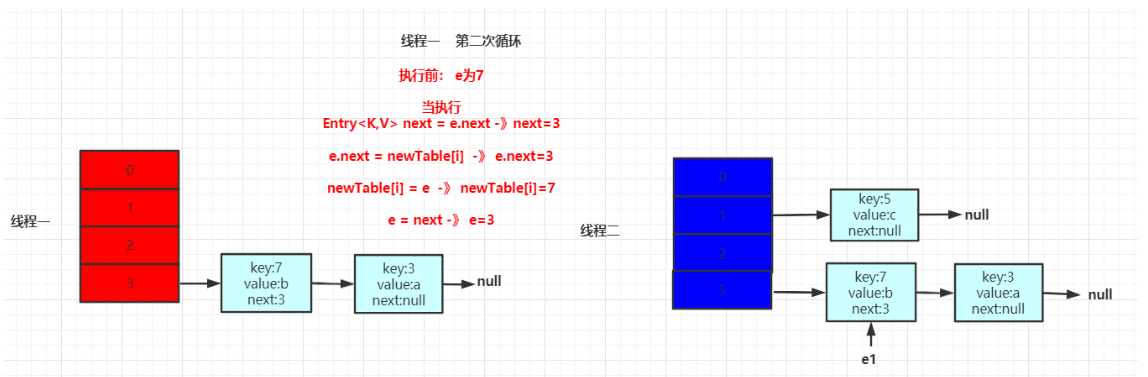
接着继续循环执行,效果如下所示:
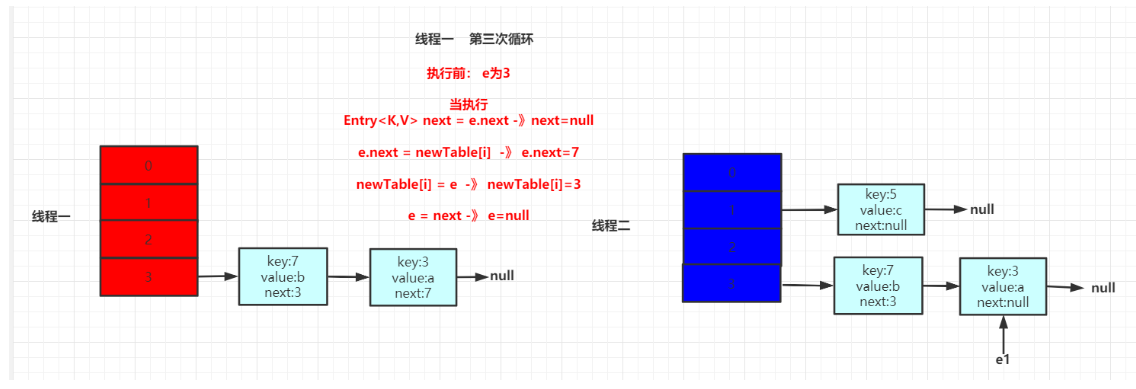
此时可以发现,当这次循环完之后,3中的next指向7,7中的next指向3.此时死循环已经出现。
JDK8的HashMap
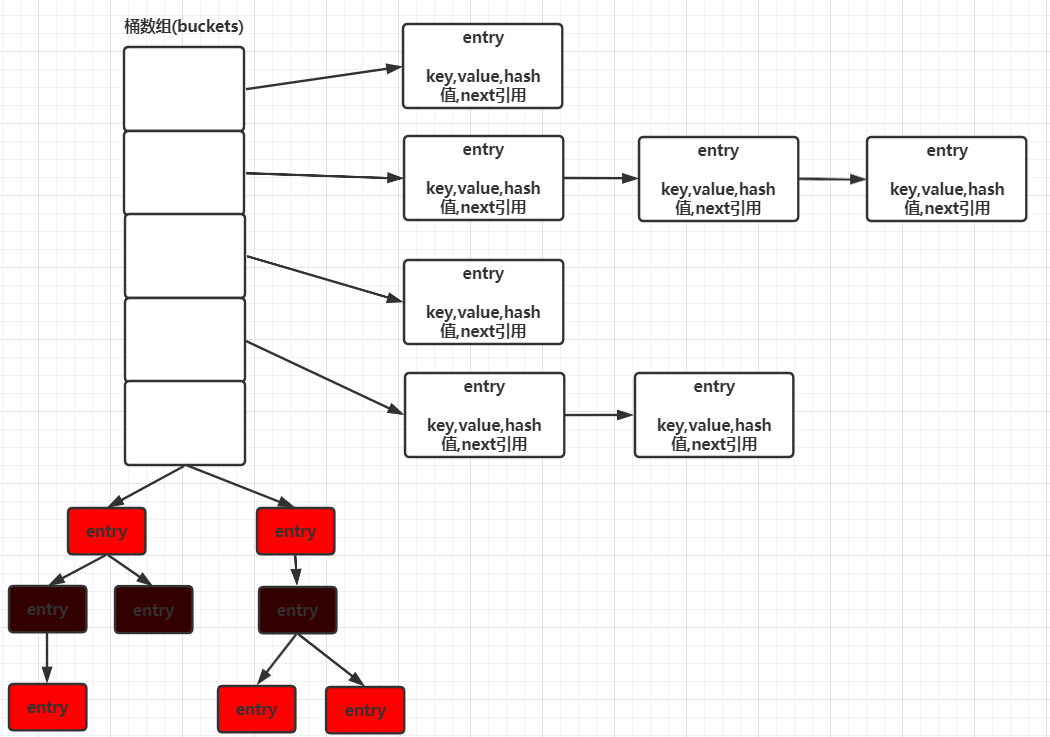
JDK8中对于HashMap的存储结构进行了优化,由数组+链表+红黑树组成。这么做的原因是因为:之前查找元素需要遍历链表,时间复杂度取决于链表的长度。
为了优化这部分的开销,在JDK中,如果链表中元素大于等于8个,则将链表转换为红黑树(前提是桶的大小达到64,否则会先对桶进行扩容);当红黑树中元素小于等于6个,则将红黑树转为链表。从而降低查询与添加的时间复杂度。
JDK8的HashMap源码分析
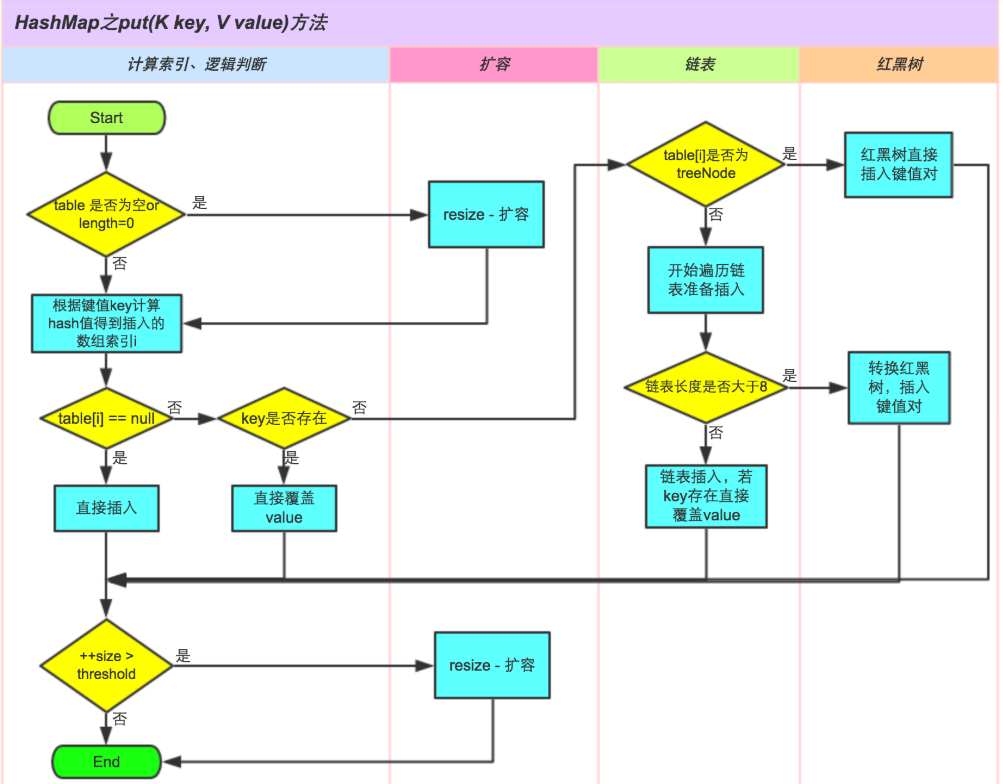
put流程
/** |
jdk 7 与 jdk 8 中关于HashMap的对比
- 8时红黑树+链表+数组的形式,当桶内元素大于8时,便会树化
- 1.7 table在创建hashmap时分配空间,而1.8在put的时候分配,如果table为空,则为table分配空间。
- 在发生冲突,插入链中时,7是头插法,8是尾插法。
知识点延伸
HashMap 的buckets长度为什么永远是 2 的幂次方
为了能让存储更加高效,尽量的避免key冲突,让数据尽量均匀的进行分布,因此采用了hash值计算的方式,hash值的范围为-2147483648 到 2147483647。在这40亿的空间中,总的来说一般很难出现碰撞。但是这么大的空间,不可能一次性全部装入内存中,所以不能直接使用这块空间。因此才会对数组长度进行取模运算,根据余数用来对应数组的下标,来确定当前用于存放数据的位置。计算公式就是(n-1)&hash。所以buckets的长度才永远为2的幂次方。
取模运算不用hash%length,而使用(length-1)&hash,是因为&采用二进制进行操作,比 % 的运算效率高。
HashMap负载因子为什么是0.75
根据之前的讲解,负载因子是和扩容机制有关的。扩容公式为:数组容量*负载因子=扩容阈值。 当buckets数组达到阈值时,则会进行扩容操作。那么为什么在hashMap中不管是JDK7还是JDK8对于扩容因子都定义为0.75呢?
HashMap总的来说就是一个数据结构,那数据结构就是为了节省空间和时间。那负载因子的作用就是为了节省空间和时间的。
假设负载因子的值为1.0。那么结合扩容公式可知,当buckets桶数组全部用完之后才会进行扩容。因为在扩容时,hash冲突是无法避免的。因此当负载因子为1.0时,在进行扩容时,会出现更多的hash冲突,可能导致链表长度或红黑树高度会变得更长或更高,导致查询效率的降低。因此负载因子过大,虽然保证了空间,但牺牲了时间。
假设负载的值为0.5。那么结合扩容公式可知,当buckets数组使用一半时,就会触发扩容。因为数组中的元素少,所以出现hash冲突的几率也会变少,所以链表长度或者是红黑树的高度就会降低,从而提升了查询效率。但是这样的话,空间利用率又降低了。原本只要1M就能存储的数据,现在则需要2M。所以负载因子太小,虽然时间效率提升了,但是空间利用率降低了。
为什么JDK8采用红黑树,而不采用平衡二叉树
因为平衡二叉树条件太苛刻了,需要一直进行整棵树的平衡进行左旋或右旋的操作,红黑树相对来讲调整的少点,只要达到黑平衡即可。并且红黑树对于节点的增删和查找效率都是较为中肯的。
为什么链表转红黑树的阈值是8
因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。因此8是一个较为合理的值。
ConcurrentHashMap解析
简介
ConcurrentHashMap是一个线程安全且高效的HashMap。在并发下,推荐使用其替换HashMap。对于它的使用也非常的简单,除了提供了线程安全的get和put之外,它还提供了一个非常有用的方法putIfAbsent,如果传入的键值对已经存在,则返回存在的value,不进行替换; 如果不存在,则添加键值对,返回null。
public class MapDemo { |
JDK7的ConcurrentHashMap
基础结构
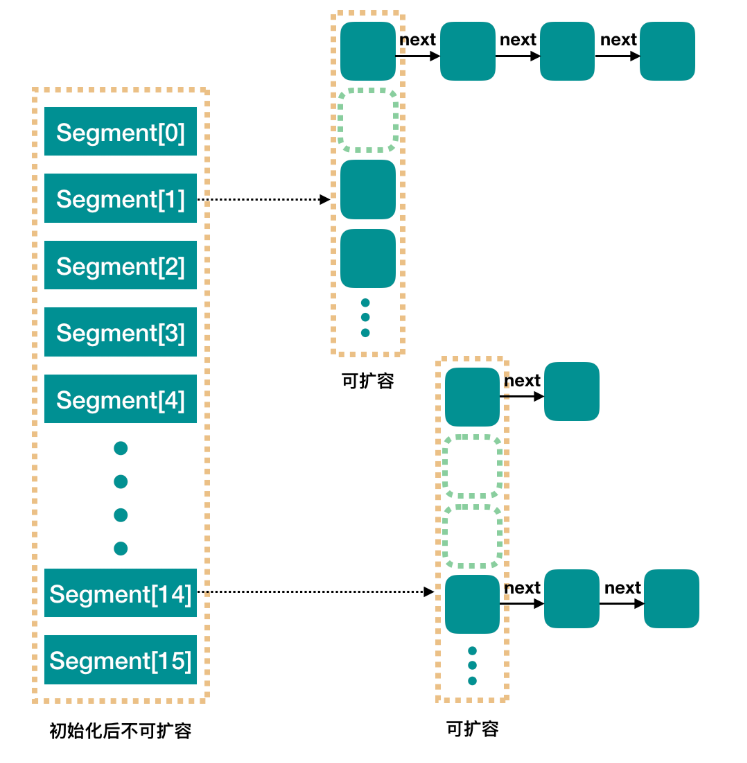
一个ConcurrentHashMap里包含一个Segment数组,结构与HashMap类似(数组+链表)。一个Segment中包含一个HashEntry数组,每个HashEntry就是链表的元素。
Segment是ConcurrentHashMap实现的很核心的存在,Segment翻译过来就是一段,一般把它称之为分段锁。它继承了ReentrantLock,在ConcurrentHashMap中相当于锁的角色,在多线程下,不同的线程操作不同的segment。只要锁住一个 segment,其他剩余的Segment依然可以操作。这样只要保证每个 Segment 是线程安全的,我们就实现了全局的线程安全。
HashEntry则用于存储键值对。

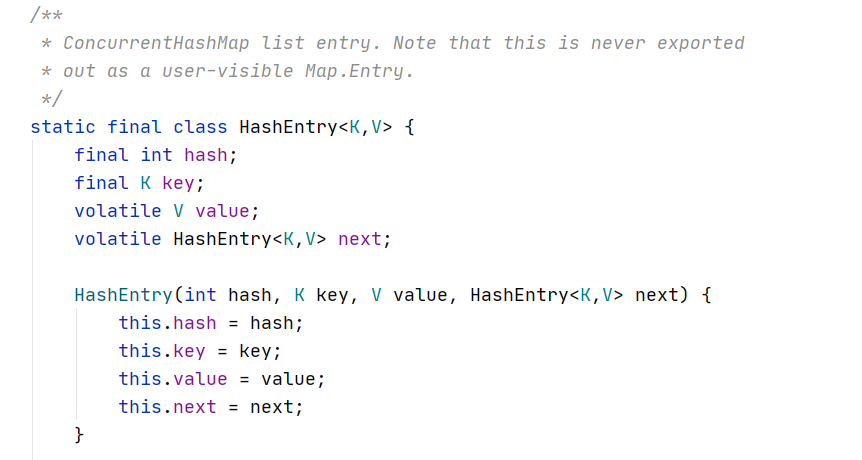
构造方法和初始化


根据其构造函数可知,map的容量默认为16,负载因子为0.75。这两个都与原HashMap相同,但不同的在于,其多个参数**concurrencyLevel(并发级别)**,通过该参数可以用来确定Segment数组的长度并且不允许扩容,默认为16。
并发度设置过小会带来严重的锁竞争问题;如果过大,原本位于一个segment内的访问会扩散到不同的segment中,导致查询命中率降低,引起性能下降。
API解析
get()
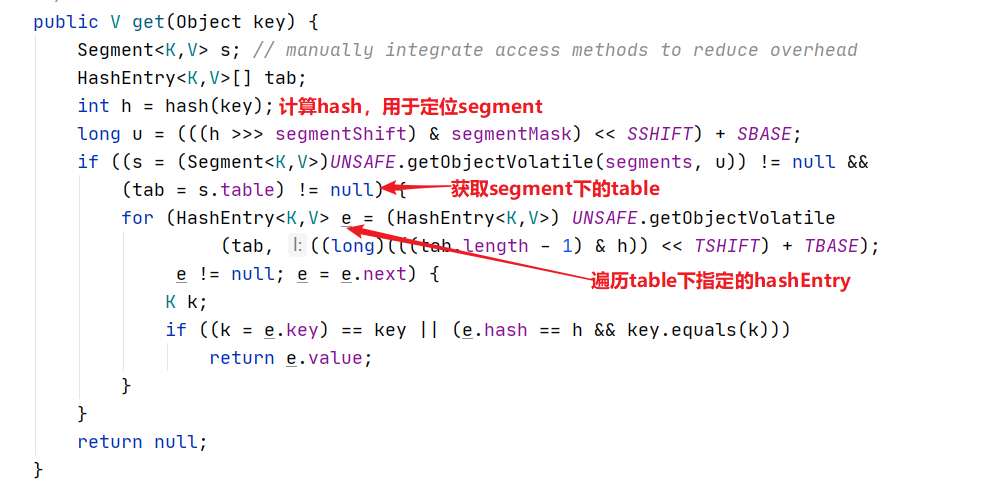
1)根据key计算出对应的segment
2)获取segment下的HashEntry数组
3)遍历获取每一个HashEntry进行比对。
注意:整个get过程没有加锁,而是通过volatile保证可以拿到最新值。
put()
初始化segment,因为ConcurrentHashMap初始化时只会初始化segment[0],对于其他的segment,在插入第一个值的时候再进行初始化。经过计算后,将对应的segment完成初始化。

向下调用ensureSegment方法,其内部可以通过cas保证线程安全,让多线程下只有一个线程可以成功。
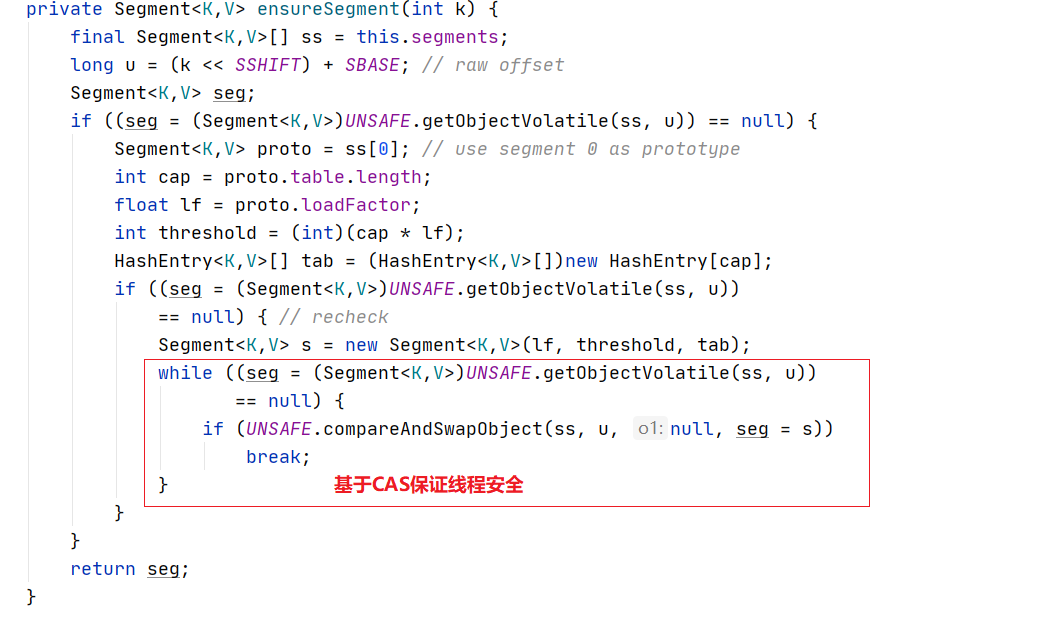
在put方法中当初始化完Segment后,会调用一个put的重载方法进行键值对存放。首先会调用tryLock()尝试获取锁,node为null进入到后续流程进行键值对存放;如果没有获取到锁,则调用**scanAndLockForPut()**自旋等待获得锁。
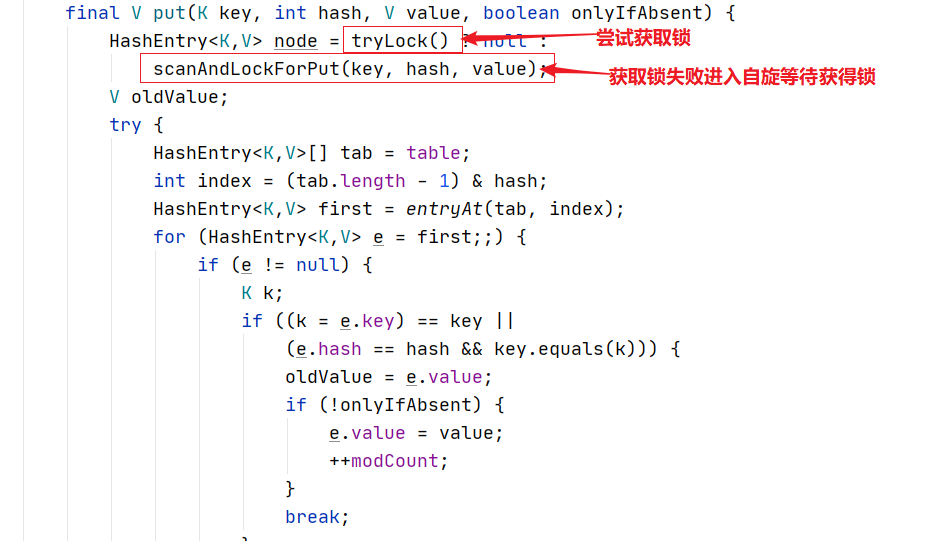
在scanAndLockForPut()方法中首先会根据链表进行遍历,如果遍历完毕仍然找不到与key相同的HashEntry,则提前创建一个HashEntry。当tryLock一定次数后仍然无法获得锁,则主动通过lock申请锁。

在获得锁后,segment对链表进行遍历,如果某个 HashEntry 节点具有相同的 key,则更新该 HashEntry 的 value 值,否则新建一个节点将其插入链表头部。
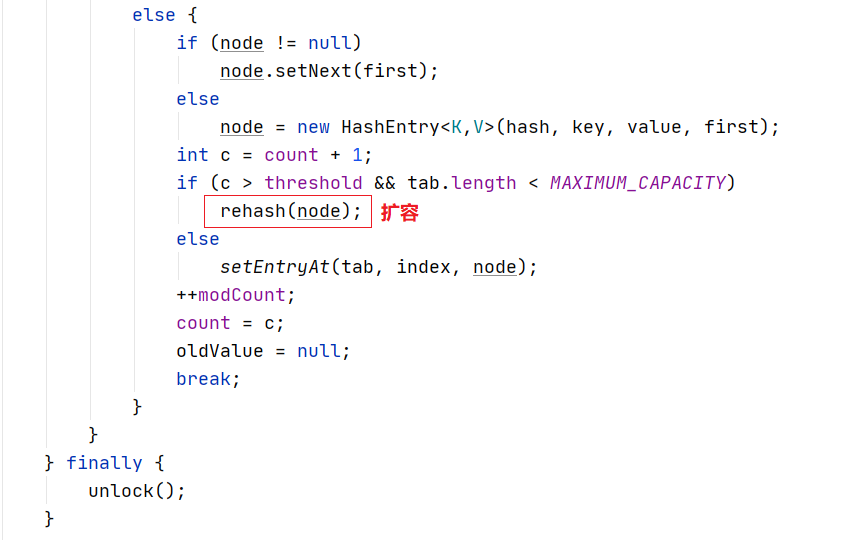
如果节点总数超过阈值,则调用rehash()进行扩容。
JDK8的ConcurrentHashMap
与JDK7的区别
在JDK1.8中对于ConcurrentHashMap也进行了升级,主要优化点如下:
1)JDK7中使用CAS+Reentrant保证并发更新的安全,而在JDK8是通过CAS+synchronized保证。因为synchronized拥有了优化,在低粒度加锁下,synchronized并不比Reentrant差;在大量数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存。
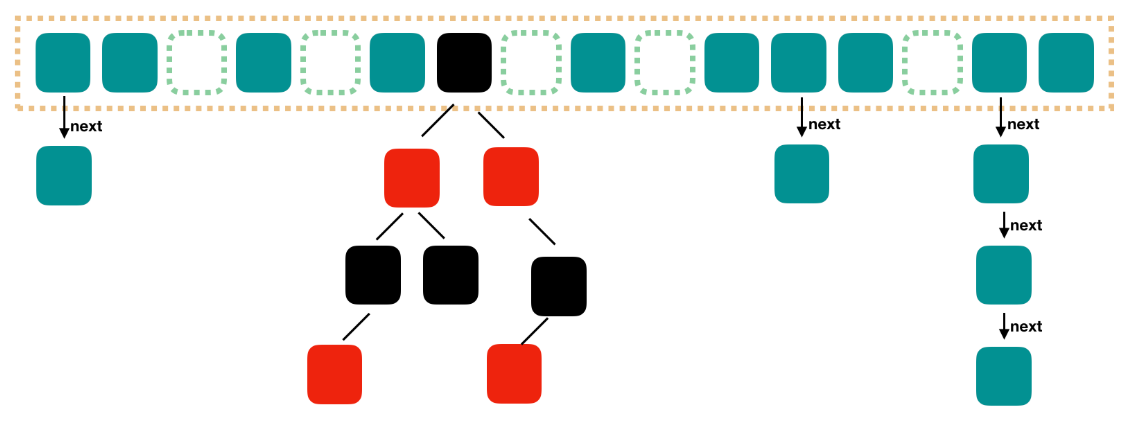
2)JDK7的底层使用segment+数组+链表组成。而在JDK8中抛弃了segment,转而使用数组+链表+红黑树的形式实现,从而让锁的粒度能够更细,进一步减少并发冲突的概率;同时也提高的数据查询效率。
3)在JDK7中的HashEntry在JDK8中变为Node,当转化为红黑树后,变为TreeNode。转换的规则与hashMap相同,当链表长度大于等于8则转换为红黑树,当红黑树的深度小于等于6则转换为链表。
核心属性
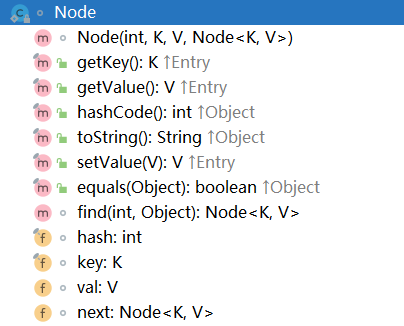
Node类:用于存储键值对。其与JDK7中的HashEntry属性基本相同。
TreeNode类:树节点类,当链表长度大于等于8,则转换为TreeNode。与hashMap不同的地方在于,它并不是直接转换为红黑树,而是把这些节点放在TreeBin对象中,由TreeBin完成红黑树的包装。

TreeBin类:负责TreeNode节点包装,它代替了TreeNode的根节点,也就是说在实际的数组中存放的是TreeBin对象,而不是TreeNode对象。
sizeCtl属性:用于控制table的初始化和扩容。-1表示正在初始化,-N表示由N-1个线程正在进行扩容,0为默认值表示table还没被初始化,正数表示初始化大小或Map中的元素达到这个数量时,则需要扩容了。
核心API
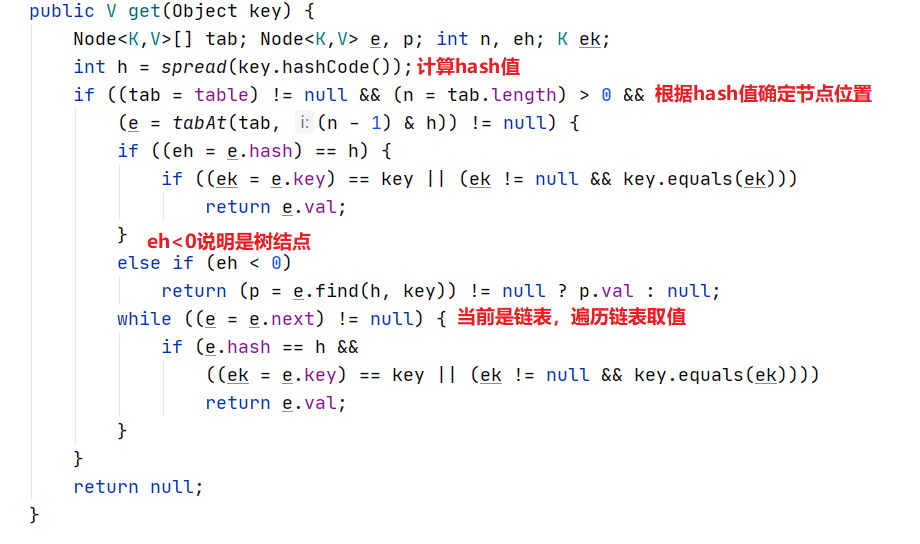
get()
get操作的思路比较简单,和HashMap取值过程类似。
put()
put操作较为复杂,需要考虑并发安全性的问题。
/** Implementation for put and putIfAbsent */ |
与hashTable的区别
Hashtable的任何操作都会把整个表锁住,是阻塞的。好处是总能获取最实时的更新,比如说线程A调用putAll写入大量数据,期间线程B调用get,线程B就会被阻塞,直到线程A完成putAll,因此线程B肯定能获取到线程A写入的完整数据。坏处是所有调用都要排队,竞争越激烈效率越低。 更注重安全。
ConcurrentHashMap 是设计为非阻塞的。在更新时会局部锁住某部分数据,但不会把整个表都锁住。同步读取操作则是完全非阻塞的。好处是在保证合理的同步前提下,效率很高。坏处 是严格来说读取操作不能保证反映最近的更新。例如线程A调用putAll写入大量数据,期间线程B调用get,则只能get到目前为止已经顺利插入的部分数据。更注重性能。






