Elasticsearch入门级学习

Elasticsearch入门级学习
jwangElasticSearch简介
什么是ElasticSearch?
- ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题及可能出现的更多其它问题。
ElaticSearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
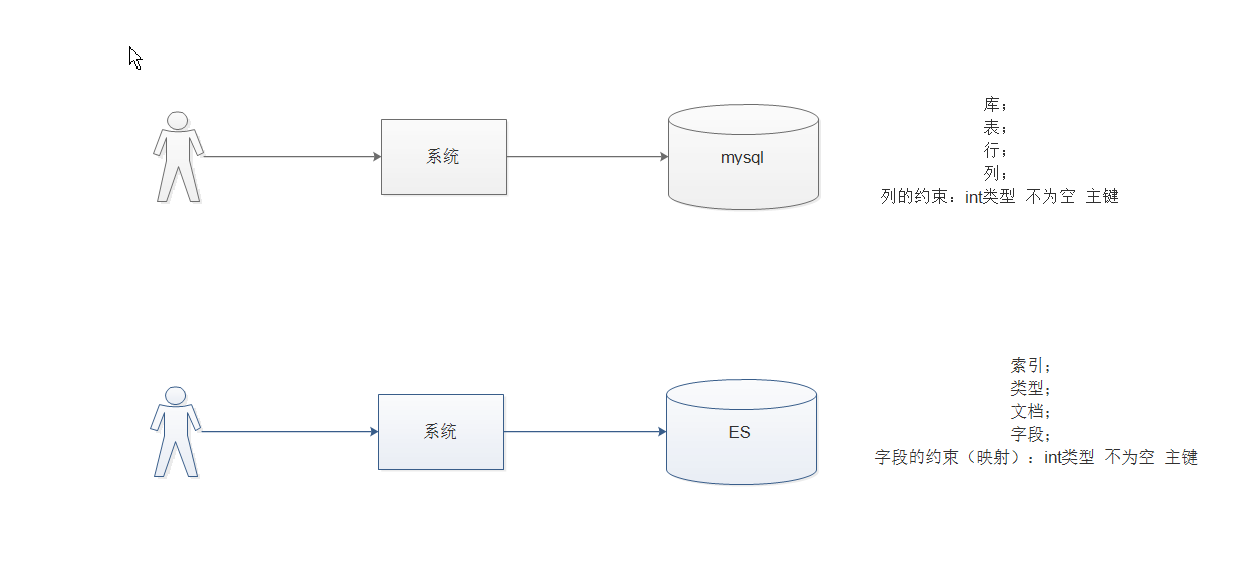
elasticsearch相当于数据库。
ElasticSearch的使用案例
2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”
维基百科:启动以elasticsearch为基础的核心搜索架构
SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云析分、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
新浪:使用ES 分析处理32亿条实时日志
阿里:使用ES 构建挖财自己的日志采集和分析体系
ElasticSearch对比Solr
Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多由第三方插件提供;
Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch;
Elasticsearch支持RestFul风格编程(uri的地址,就可以检索),Solr暂不支持;
理解倒排索引
- 通常我们搜索某些东西,是通过内容,找词 这样容易区分,这种方式成为正向搜索,那么数据量大就效率低,那么还有一种就是倒排索引方式,可以通过词去找内容,这样速度就非常快了。如下图所示:
https://www.gushiwen.org/shiju/shui.aspx
- 文章数据如下:
一篇文章1 |

- 要建立倒排索引表,需要先对文本进行分词(理解成按照一定规则拆分出词条和值),也就是将词语进行切分然后形成如上的结构和映射关系。比如下边
临 ---->文章数据 |
- 那么这个过程就是分词,分词的过程需要有分词器来进行。我们有许多的分词器,默认就是标准分词器。
ElasticSearch安装与启动
下载ES压缩包
ElasticSearch分为Linux和Window版本,基于我们主要学习的是ElasticSearch的Java客户端的使用,所以我们课程中使用的是安装较为简便的Window版本,项目上线后,公司的运维人员会安装Linux版的ES供我们连接使用。
ElasticSearch的官方地址: https://www.elastic.co/products/elasticsearch

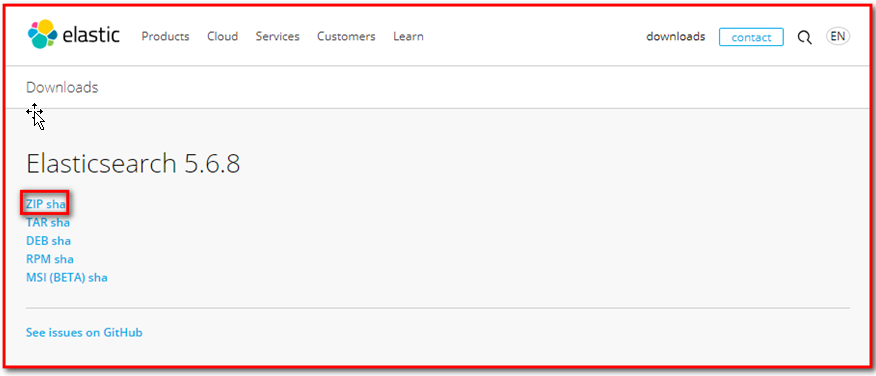
已经下载好了如下图:
安装ES服务
Window版的ElasticSearch的安装很简单,类似Window版的Tomcat,解压开即安装完毕,解压后的ElasticSearch的目录结构如下:
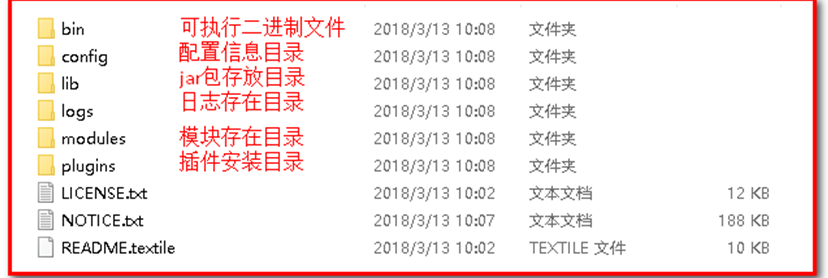
注意:ES的目录不要出现中文,也不要有特殊字符。
启动ES服务
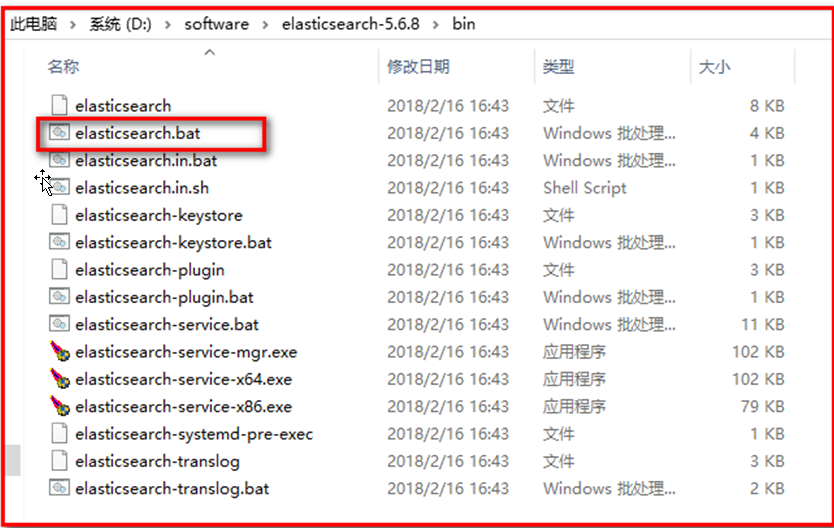
启动:
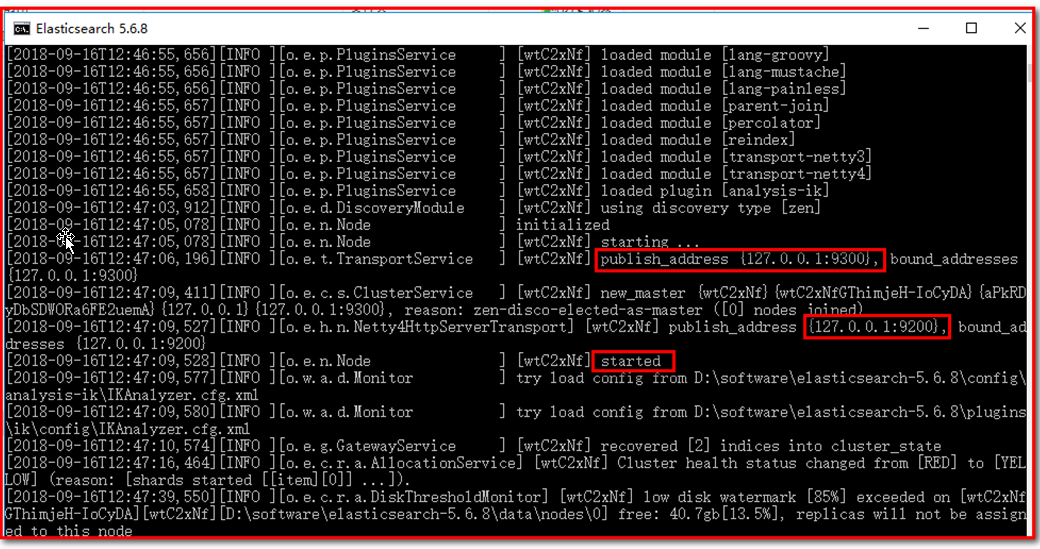
注意:
9300是tcp通讯端口,集群间和TCPClient都执行该端口,可供java程序调用;
9200是http协议的RESTful接口 。
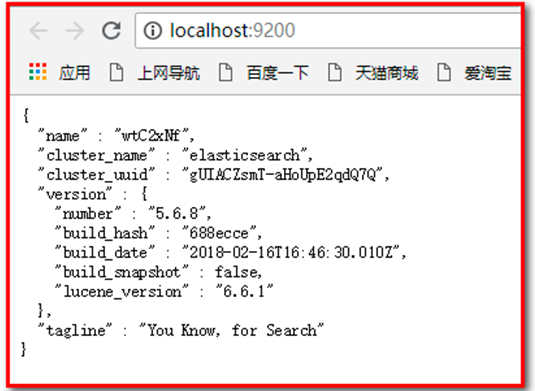
通过浏览器访问ElasticSearch服务器,看到如下返回的json信息,代表服务启动成功:
注意事项:
(1)ElasticSearch5是使用java开发的,且本版本的es需要的jdk版本要是1.8以上,所以安装ElasticSearch之前保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败
(2)出现闪退,通过路径访问发现“空间不足”
修改:解压目录下的/config/jvm.options文件

安装ES的图形化界面插件
ElasticSearch不同于Solr自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效果,完成索引数据的查看。
*elasticsearch-5-以上版本安装head插件,需要先安装 nodejs 以及 grunt
安装nodejs

下载nodejs:https://nodejs.org/en/download/
双击如图所示msi文件,下一步即可。安装成功后,执行cmd命令查看版本:
node -v |
安装 grunt:
Grunt是基于Node.js的项目构建工具;是基于javaScript上的一个很强大的前端自动化工具,基于NodeJs用于自动化构建、测试、生成文档的项目管理工具,在cmd命令行中执行以下命令:

npm install -g grunt-cli |
安装ES head 插件
1)下载head插件:https://github.com/mobz/elasticsearch-head
2)解压zip
解压zip包,并在解压目录下执行cmd命令:
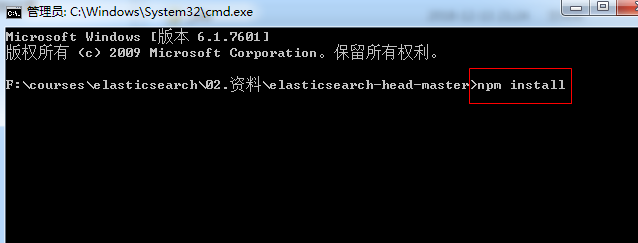
npm install |
执行完成 等待结果:
ps:如果安装不成功或者安装速度慢,可以使用淘宝的镜像进行安装:
npm install -g cnpm –-registry=https://registry.npm.taobao.org |
后续使用的时候,只需要把npm xxx 换成 cnpm xxx 即可
配置ES支持head插件
修改elasticsearch/config下的配置文件:elasticsearch.yml,增加以下配置:
http.cors.enabled: true |
注意有空格:
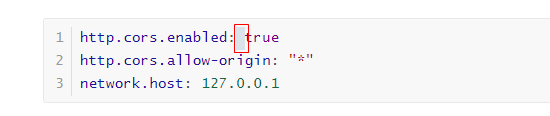
解释:
http.cors.enabled: true:此步为允许elasticsearch跨域访问,默认是false。 |
访问head插件
1) 重启ES服务器
2)进入head插件的目录 执行cmd命令:
npm run start |