
MongoDB

MongoDB
jwangMongoDB简介
为什么要使用MongoDB
文章评论功能存在以下特点:
- 数据量大
- 写入操作频繁
- 价值较低
对于这样的数据,我们更适合使用MongoDB来实现数据的存储
什么是MongoDB
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供==可扩展的高性能数据存储解决方案==。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson(数据类型)格式,因此可以存储比较复杂的数据类型。
MongoDB特点
Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。(正则表达式支持索引)
它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
- 面向集合存储,易存储对象类型的数据。(集合相当于表)
- 模式自由。
- 支持动态查询。
- 支持完全索引,包含内部对象。
- 支持查询。
- 支持复制和故障恢复。(高可用)
- 使用高效的二进制数据存储,包括大型对象(如视频等)。
- 自动处理碎片,以支持云计算层次的扩展性。(mapreduce)
- 支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- 文件存储格式为BSON(一种JSON的扩展)。
MongoDB体系结构
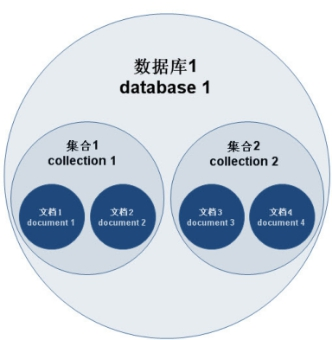
MongoDB 的逻辑结构是一种层次结构。主要由:**文档(document)、集合(collection)、数据库(database)**这三部分组成的。逻辑结构是面向用户的,用户使用 MongoDB 开发应用程序使用的就是逻辑结构。
- MongoDB 的文档(document),相当于关系数据库中的一行记录。
- 多个文档组成一个集合(collection),相当于关系数据库的表。
- 多个集合(collection),逻辑上组织在一起,就是数据库(database)。
- 一个 MongoDB 实例支持多个数据库(database)。
文档(document)、集合(collection)、数据库(database)的层次结构如下图:
| MongoDb | 关系型数据库Mysql |
|---|---|
| 数据库(databases) | 数据库(databases) |
| 集合(collections) | 表(table) |
| 文档(document) | 行(row) |
MongoDB数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
特殊说明:
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
时间戳
BSON 有一个特殊的时间戳类型,与普通的日期类型不相关。时间戳值是一个 64 位的值。其中:
- 前32位是一个 time_t 值【与Unix新纪元(1970年1月1日)相差的秒数】
- 后32位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳值通常是唯一的。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。

MongoDB和Redis比较
| 比较指标 | MongoDB(海量数据) | Redis(热点数据) | 比较说明 |
|---|---|---|---|
| 实现语言 | c++ | c/c++ | - |
| 协议 | ==BSON,自定义二进制== | ==类telnet(TCP/IP)== | - |
| 性能 | ==依赖内存 (内存映射文件技术)== | ==依赖内存==(纯内存) | Redis优于MongoDB |
| 可操作性 | 丰富的数据表达,索引;最类似于关系型数据库,支持丰富的查询语句 | 数据类型丰富,较少的IO | - |
| 内存及存储 | 适合大数据量存储,依赖系统虚拟内存,采用镜像文件存储;内存占用率比较高,官方建议独立部署在64位系统 | Redis2.0后支持虚拟内存特性(VM) 突破物理内存限制;数据可以设置时效性,类似于memcache | 不同的应用场景,各有千秋 |
| 可用性 | 支持master-slave,replicatset(内部采用paxos选举算法,自动故障恢复),auto sharding机制,对客户端屏蔽了故障转移和切片机制 | 依赖客户端来实现分布式读写;主从复制时,每次从节点重新连接主节点都要依赖整个快照,无增量复制;不支持auto sharding,需要依赖程序设定一致性hash机制 | MongoDB优于Redis;单点问题上,MongoDB应用简单,相对用户透明,Redis比较复杂,需要客户端主动解决.(MongoDB一般使用replicasets和sharding相结合,replicasets侧重高可用性以及高可靠,sharding侧重性能,水平扩展) |
| 可靠性 | 从1.8版本后,采用binlog方式(类似Mysql) 支持持久化 | 依赖快照进行持久化;AOF增强可靠性;增强性的同时,影响访问性能 | mongodb在启动时,专门初始化一个线程不断循环(除非应用crash掉),用于在一定时间周期内来从defer队列中获取要持久化的数据并写入到磁盘的journal(日志)和mongofile(数据)处,当然它不是在用户添加记录时就写到磁盘上 |
| 一致性 | ==以前版本不支持事务,靠客户端保证== ==最新4.x的支持事务== | ==支持事务,比较脆,仅能保证事务中的操作按顺序执行== | - |
| 数据分析 | 内置数据分析功能(mapreduce) | 不支持 | MongoDB优于Redis |
| 应用场景 | ==海量数据存储和访问效率提升== | ==热点数据的存储== | - |
MongoDB安装
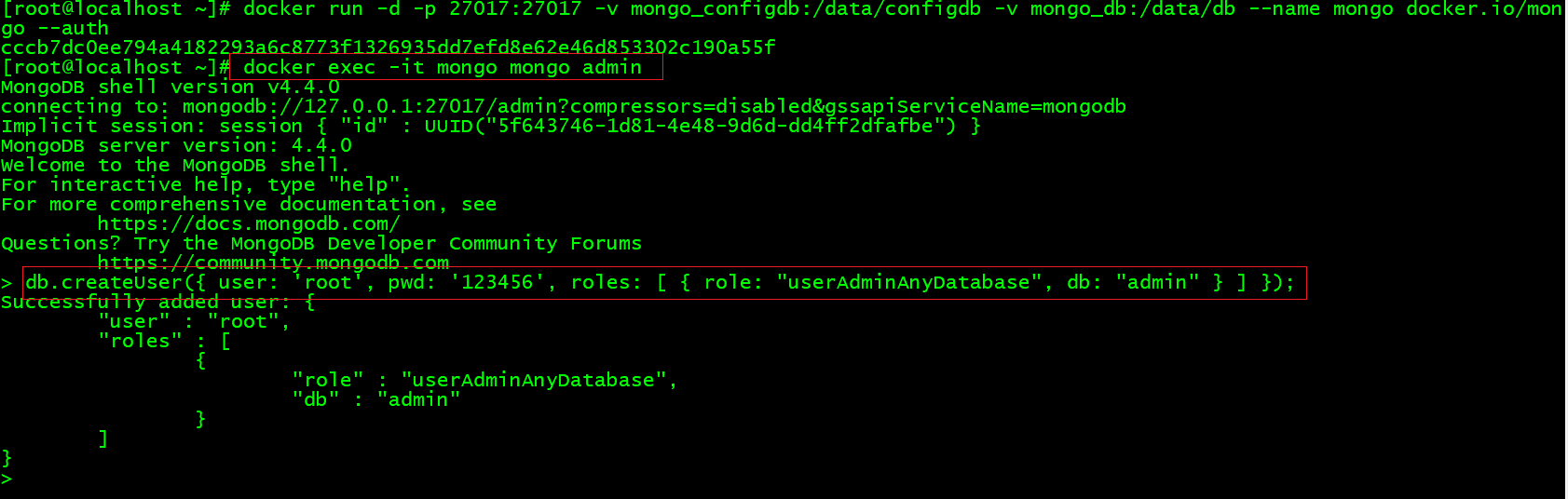
Docker 环境下MongoDB安装
在Linux虚拟机中创建mongo容器,命令如下:
#下载mongo镜像 |
客户端的安装和使用
studio3t是mongodb优秀的客户端工具。官方地址在https://studio3t.com/
下载studio3t
安装并启动:

创建一个新连接:
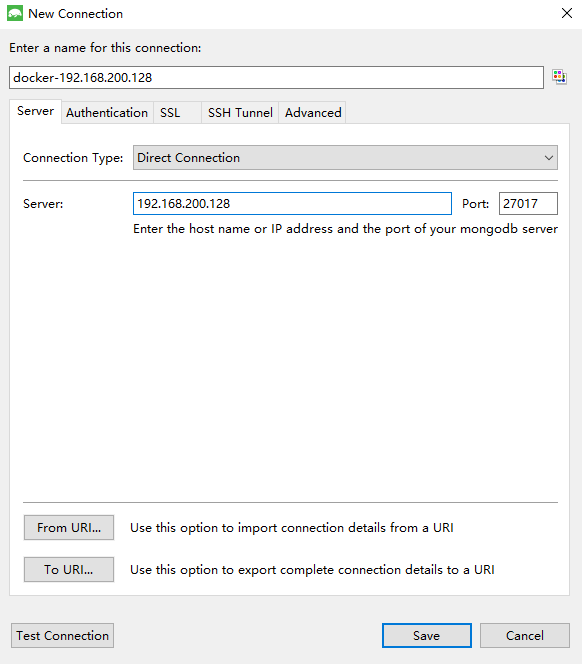
连接成功:
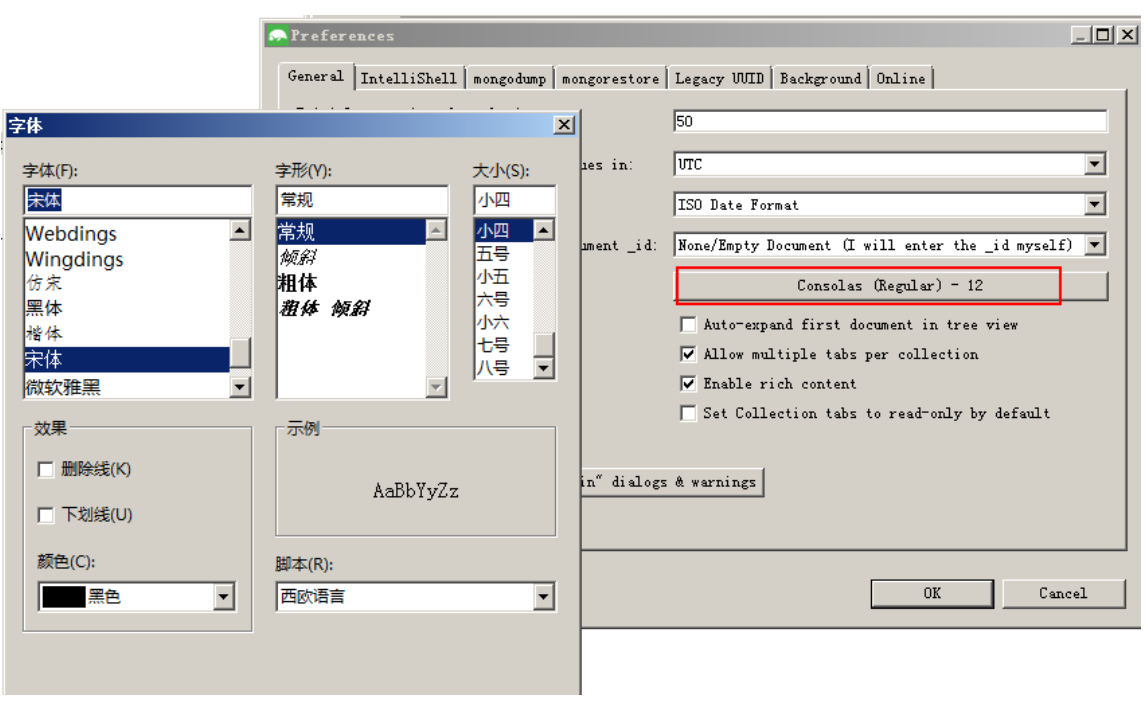
修改字体:
默认Studio3t的字体太小,需要修改字体:
点击菜单:Edit—>Preferences
常用命令
选择和创建数据库
连接mongodb客户端
docker exec -it cccb7dc0ee79 /bin/bash |
选择和创建数据库的语法格式:
use 数据库名称 |
如果数据库存在则选择该数据库,如果数据库不存在则自动创建。以下语句创建commentdb数据库:
use commentdb |
查看数据库:
show dbs |
查看集合,需要先选择数据库之后,才能查看该数据库的集合:
show collections |
创建集合
db.createCollection(name, options) |
db.createCollection("comment") |
插入与查询文档
选择数据库后,使用集合来对文档进行操作,插入文档语法格式:
db.集合名称.insert(数据); |
插入以下测试数据:
db.comment.insert({content:"加强课",userid:"1011"}) |
查询集合的语法格式:
db.集合名称.find() |
查询集合的所有文档,输入以下命令:
db.comment.find() |
发现文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB会自动创建,其类型是ObjectID类型。如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型。
输入以下测试语句:
db.comment.insert({_id:"1",content:"到底为啥出错",username:"张三",userid:"1012",thumbup:2020,tags:["很好","十分认同"],tupuser:[{name:"李大",sex:"女",age:10},{name:"李二",sex:"男",age:42}],lastModifiedDate:new Date()}); |
按一定条件来查询,比如查询userid为1013的记录,只要在find()中添加参数即可,参数也是json格式,如下:
db.comment.find({userid:'1013'}) |
只需要返回符合条件的第一条数据,我们可以使用findOne命令来实现:
db.comment.findOne({userid:'1013'}) |
返回指定条数的记录,可以在find方法后调用limit来返回结果,例如:
db.comment.find().limit(2) |
修改与删除文档
修改文档的语法结构:
db.集合名称.update(条件,修改后的数据) |
修改_id为1的记录,点赞数为1000,输入以下语句:
db.comment.update({_id:"1"},{thumbup:1000}) |
执行后发现,这条文档除了thumbup字段其它字段都不见了。
为了解决这个问题,我们需要使用修改器**$set**来实现,命令如下:
db.comment.update({_id:"2"},{$set:{thumbup:2000}}) |
删除文档的语法结构:
db.集合名称.remove(条件) |
以下语句可以将数据全部删除,慎用~
db.comment.remove({}) |
删除条件可以放到大括号中,例如删除thumbup为1000的数据,输入以下语句:
db.comment.remove({thumbup:1000}) |
###1.4 统计条数
统计记录条件使用count()方法。以下语句统计集合的记录数:
db.comment.count() |
按条件统计 ,例如统计userid为1013的记录条数:
db.comment.count({userid:"1013"}) |
1.5 模糊查询
MongoDB的模糊查询是通过正则表达式的方式实现的。格式为:
/模糊查询字符串/ |
查询评论内容包含“流量”的所有文档,代码如下:
db.comment.find({content:/流量/}) |
查询评论内容中以“加班”开头的,代码如下:
db.comment.find({content:/^加班/}) |
1.6 大于 小于 不等于
<, <=, >, >= 这个操作符也是很常用的,格式如下:
db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value |
查询评论点赞数大于1000的记录:
db.comment.find({thumbup:{$gt:1000}}) |
###1.7 包含与不包含
包含使用**$in**操作符
查询评论集合中userid字段包含1013和1014的文档:
db.comment.find({userid:{$in:["1013","1014"]}}) |
不包含使用**$nin**操作符
查询评论集合中userid字段不包含1013和1014的文档:
db.comment.find({userid:{$nin:["1013","1014"]}}) |
条件连接
我们如果需要查询同时满足两个以上条件,需要使用**$and**操作符将条件进行关联(相当于SQL的and)。格式为:
$and:[ {条件},{条件},{条件} ] |
查询评论集合中thumbup大于等于1000 并且小于2000的文档:
db.comment.find({$and:[ {thumbup:{$gte:1000}} ,{thumbup:{$lt:2000} }]}) |
如果两个以上条件之间是或者的关系,我们使用操作符进行关联,与前面and的使用方式相同,格式为:
$or:[ {条件},{条件},{条件} ] |
查询评论集合中userid为1013,或者点赞数小于2000的文档记录:
db.comment.find({$or:[ {userid:"1013"} ,{thumbup:{$lt:2000} }]}) |
列值增长
对某列值在原有值的基础上进行增加或减少,可以使用**$inc**运算符:
db.comment.update({_id:"2"},{$inc:{thumbup:1}}) |
索引的使用
索引简介
索引支持在MongoDB中高效执行查询。没有索引,MongoDB必须执行全表扫描,即扫描集合中的每个文档,以选择与查询语句匹配的那些文档。如果查询存在适当的索引,则MongoDB可以使用该索引来限制它必须检查的文档数。索引是特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。索引存储一个特定字段或一组字段的值,按该字段的值排序。索引条目的排序支持有效的相等匹配和基于范围的查询操作。另外,MongoDB可以使用索引中的顺序返回排序的结果。
下图说明了使用索引选择和排序匹配文档的查询:

从根本上讲,MongoDB中的索引类似于其他数据库系统中的索引。MongoDB在集合 级别定义索引,并支持MongoDB集合中文档的任何字段或子字段的索引。
索引基本操作
创建索引
基本语法
db.collection.createIndex(keys, options) |
keys:可写为要配置索引的字段如{“articleid”:1},其中,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。但是字段不能指定为_id,因为该字段默认会创建索引。
注意: 注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
options:表示创建索引时的设置,这个在索引属性中单独说明:
ex:
//为articleid字段创建升序索引 |
也可以创建多个字段的联合索引,比如:
//创建article升序字段和userid降序字段的联合索引 |
这种索引只支持:
db.comment.find().sort({“articleid”:1,”userid”:-1})或者db.comment.find().sort({“articleid”:-1,”userid”:1})的查询使用该索引,其他情况如db.comment.find().sort({“articleid”:1,”userid”:1})则不能使用,这种情景和关系型数据库中的联合索引表现是一致的。 有关排序顺序和复合索引的更多信息,请参见 使用索引对查询结果进行排序。
查看索引
查看当前数据库中该集合的所有索引
db.comment.getIndexes() |
或者
db.comment.aggregate( [ { $indexStats: { } } ] ) |
删除索引
删除所有索引
db.comment.dropIndexes() |
删除指定索引
db.comment.dropIndex(索引名称) |
修改索引
要修改现有索引,您需要删除并重新创建索引。TTL索引是此规则的例外 ,可以通过collMod命令与index收集标志一起 修改TTL索引。
索引属性
索引属性参数列表:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
唯一索引
唯一索引可确保索引字段不会存储重复值;即对索引字段实施唯一性。默认情况下, 在创建集合期间,MongoDB在_id字段上创建唯一索引。
//创建articleid字段的唯一索引 |
和mysql一样,复合索引也可创建为唯一索引
部分索引
3.2版中的新功能。
部分索引仅索引集合中符合指定过滤器表达式的文档。通过索引集合中文档的子集,部分索引具有较低的存储需求,并降低了索引创建和维护的性能成本。
要创建部分索引,请将该 db.collection.createIndex()方法与 partialFilterExpression选项一起使用。该partialFilterExpression 选项接受使用以下命令指定过滤条件的文档
ex:只给该集合点赞数大于900的评论的thumbup字段创建索引
db.comment.createIndex( |
TTL指数
TTL索引是特殊的单字段索引,MongoDB可以使用它们在一定时间后或在特定时间自动从集合中删除文档。数据到期对于某些类型的信息很有用,例如机器生成的事件数据,日志和会话信息,它们仅需要在数据库中保留有限的时间。
要创建TTL索引,请将该db.collection.createIndex() 方法与expireAfterSeconds选项结合使用,该方法的值(索引字段类型)是日期或包含日期值的数组。ex:
//当前时间如果在lastModifiedDate的10s之后,则标记该文档过期 |
mongo后台的TTL线程会每隔60s删除一次被ttl索引标记为过期的文档
索引分析
//对查询进行分析 |
作用和mysql的explain关键字一样都是用来分析执行计划的
queryPlanner:执行计划
- winningPlan:竞争成功的计划
- 如果该计划使用了索引,会有以下参数
- indexName:索引名称
- isMultiKey:是否为多键索引
- isUnique:是否唯一索引
- isSparse:是否是稀疏索引
- isPartial:是否是部分索引
- 如果没有以上参数,表示没有使用索引
- 如果该计划使用了索引,会有以下参数
- rejectedPlans:竞争失败的计划
- winningPlan:竞争成功的计划
mongo聚合查询
MongoDB的聚合框架以数据处理管道的概念为模型。文档进入多阶段流水线,该流水线将文档转换成汇总结果。例如:
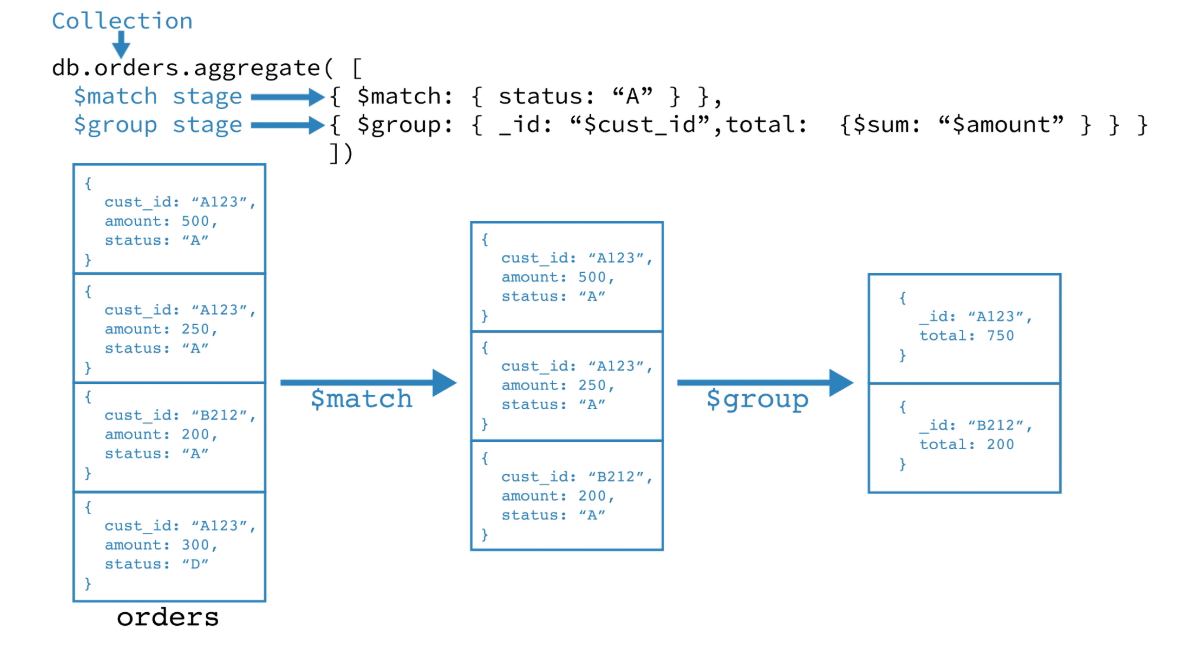
在这个例子中
db.orders.aggregate([ |
第一阶段:$match阶段按status字段过滤文档,并将status等于的文档传递到下一阶段"A"。
第二阶段:该$group阶段按cust_id字段将文档分组,以计算每个唯一值的总和cust_id。
最基本的管道阶段提供过滤器,其操作类似于查询和修改输出文档形式的文档转换。
其他管道操作提供了用于按特定字段对文档进行分组和排序的工具,以及用于聚合包括文档数组在内的数组内容的工具。另外,管道阶段可以将运算符用于诸如计算平均值或连接字符串之类的任务。
管道使用MongoDB中的本机操作提供有效的数据聚合,并且是MongoDB中数据聚合的首选方法。
聚合管道可以操作 分片集合。
聚合管道可以在某些阶段使用索引来提高其性能。另外,聚合管道具有内部优化阶段。有关详细信息,请参见管道运算符和索引以及 聚合管道优化。
ex:获取当前点赞数大于200并统计用户的总点赞数
db.comment.aggregate([ |
mongodb-driver使用
mongodb-driver是mongo官方推出的java连接mongoDB的驱动包,相当于JDBC驱动。我们现在来使用mongodb-driver完成对Mongodb的操作。
添加以下依赖:
<dependencies> |
使用步骤:
- 创建客户端连接 mongoclient
- 获取数据库
- 获取集合
- 操作集合
查询所有
|
根据_id查询
每次使用都要用到MongoCollection,进行抽取:
private MongoClient client; |
测试根据_id查询:
|
新增
|
1.4 修改
|
删除
|





