高可用简介 以主主架构为例,现在不管写或者读,只要其中一个宕机,则会把它本身工作交给另外一台服务器完成。此时就需要对IP进行一个自动的指向。而且这种服务器IP切换,对于上层应用来说,应该是完全隐藏的,其无需知道当前是由谁来完成具体工作,其只需要来连接一个IP就可以。
对于这种需求,就需要通过keepAlived 来完成IP的自动切换。
对于keepalived会在多台mysql服务器进行安装, 同时keepalived间也分为master和slave, 同时master会虚拟化一个VIP供应用进行连接。 如果一旦master挂掉后,会由slave节点继续工作,同时slave节点也会虚拟出相同VIP,供应用进行连接
keepAlived高可用配置 1)安装keepalived
1. 下载keepalied安装包 http://www.keepalived.org/download.html 2. yum -y install openssl-devel gcc gcc-c++ 3. mkdir /etc/keepalived 4. 上传安装包并解压 tar -zxvf keepalived-2.0.18.tar.gz 5. mv keepalived-2.0.18 /usr/local/keepalived 6. cd /usr/local/keepalived 7. ./configure && make && make install 8.创建启动文件 cp -a /usr/local/etc/keepalived /etc/init.d/ cp -a /usr/local/etc/sysconfig/keepalived /etc/sysconfig/ cp -a /usr/local/sbin/keepalived /usr/sbin/
2)编写执行shell脚本
进入/etc/keepalived。创建chk.sh ,同时赋予执行权限:chmod +x chk.sh
# ! /bin/bash mysql -h 192.168.200.180 -u root -p123456 -P 3312 -e "show status;" >/dev/null 2>&1 if [ $? == 0 ] then echo " $host mysql login successfully " exit 0 else echo " mysql login faild" killall keepalived exit 2 fi
3)编写keepAlived配置文件
cd /etc/keepalived vi keepalived.conf ! Configuration File for keepalived #简单的头部,这里主要可以做邮件通知报警等的设置,此处就暂不配置了; global_defs { #notificationd LVS_DEVEL router_id MYSQL_4 #唯一标识不允许出现重复 script_user root enable_script_security } #预先定义一个脚本,方便后面调用,也可以定义多个,方便选择; vrrp_script chk_haproxy { script "/etc/keepalived/chk.sh" interval 2 #脚本循环运行间隔 } #VRRP虚拟路由冗余协议配置 vrrp_instance VI_1 { #VI_1 是自定义的名称; state BACKUP #MASTER表示是一台主设备,BACKUP表示为备用设备【我们这里因为设置为开启不抢占,所以都设置为备用】 nopreempt #开启不抢占 interface ens33 #指定VIP需要绑定的物理网卡 virtual_router_id 11 #VRID虚拟路由标识,也叫做分组名称,该组内的设备需要相同 priority 130 #定义这台设备的优先级 1-254;开启了不抢占,所以此处优先级必须高于另一台 advert_int 1 #生存检测时的组播信息发送间隔,组内一致 authentication { #设置验证信息,组内一致 auth_type PASS #有PASS 和 AH 两种,常用 PASS auth_pass 111111 #密码 } virtual_ipaddress { 192.168.200.200 #指定VIP地址,组内一致,可以设置多个IP } track_script { #使用在这个域中使用预先定义的脚本,上面定义的 chk_haproxy } }
7)启动keepAlived
systemctl start keepalived
8)查看keepAlived执行状态
9)可以通过tail -f /var/log/messages
10)查看ip信息,此时可以发现出现了配置的虚拟ip
11)测试
通过navicat连接mysql,但是当前连接IP为VIP。可以连接成功。
根据上述配置可知,当前连接的为142的mysql。测试添加数据。可以添加成功。
此时将142的mysql服务停止掉,再去查看145机器上的ip a,可以发现145机器上已经出现200的虚拟ip。
再去navicat中添加数据,仍可以添加成功。但此时连接的则为145的mysql了。
5)数据切分核心思想 5.1)为什么要进行数据切分 当前微服务架构非常流行,很多都会采用微服务架构对其系统进行拆分。 而虽然产生了多个微服务,但因为其用户量和数据量的问题,很有可能仍然使用的是同一个数据库。
但是随着用户量和数据量增加,就会出现很多影响数据库性能的因素,如:数据存储量、IO瓶颈、访问量瓶颈等。此时就需要将数据进行拆分,从一个库拆分成多个库。
5.2)数据拆分方式 5.2.1)垂直拆分 垂直拆分是按照业务将表进行分类并分布到不同的数据节点上。在初始进行数据拆分时,使用垂直拆分是非常直观的一种方式。
垂直拆分的优点:
拆分规则明确,按照不同的功能模块或服务分配不同的数据库。
数据维护与定位简单。
垂直拆分的缺点:
对于读写极其频繁且数据量超大的表,仍然存在存储与性能瓶颈。简单的索引此时已经无法解决问题。
会出现跨库join。
需要对代码进行重构,修改原有的事务操作。
某个表数据量达到一定程度后扩展起来较为困难
5.2.2)水平拆分 为了解决垂直拆分出现的问题,可以使用水平拆分继续横向扩展,首先,可以如果当前数据库的容量没有问题 的话,可以对读写极其频繁且数据量超大的表进行分表 操作。由一张表拆分出多张表。
在一个库中,拆分出多张表,每张表存储不同的数据,这样对于其操作效率会有明显的提升。而且因为处于同一个库中,也不会出现分布式事务的问题。
而拆分出多张表后,如果当前数据库的容量已经不够了,但是还要继续拆分的话,就可以进行分库 操作,产生多个数据库,然后在扩展出的数据库中继续扩展表。
水平拆分的优点:
尽量的避免了跨库join操作。
不会存在超大型表的性能瓶颈问题。
事务处理相对简单。
只要拆分规则定义好,很难出现扩展性的限制。
水平拆分的缺点:
拆分规则不好明确,规则一定会和业务挂钩,如根据id、根据时间等。
不好明确数据位置,难以进行维护。
多数据源管理难度加大,代码复杂度增加。
也会存在分布式事务问题
数据库维护成本增加
5.3)数据切分带来的问题
按照用户ID求模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中。
按照日期,将不同月甚至日的数据分散到不同的库中。
按照某个特定的字段求模,或者根据特定范围段分散到不同的库中。
数据切分带来的核心问题
产生引入分布式事务的问题。
跨节点 Join 的问题。
跨节点合并排序分页问题。
6)Mycat核心概念&源码部署 6.1)Mycat简介 当对数据拆分后会产生诸多的问题,对于这些问题的解决,可以借助于数据库中间件来进行解决,现在时下比较流行的是使用Mycat。
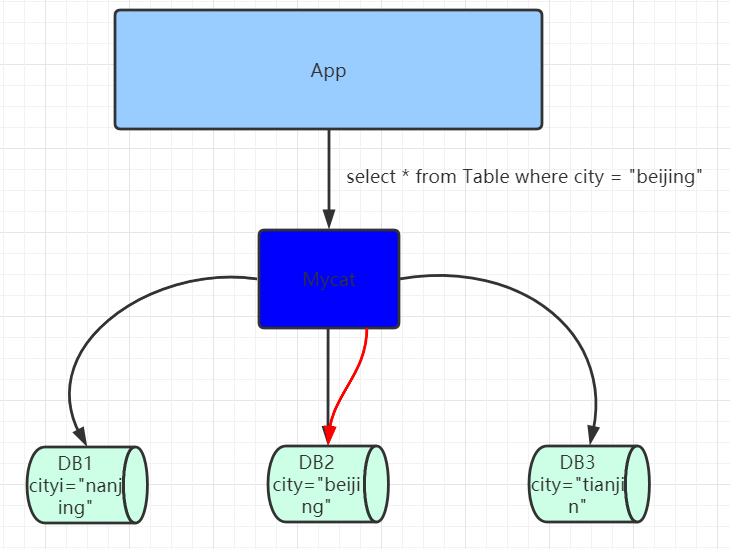
Mycat是一款数据库中间件,对于应用程序来说是完全透明化的,不管底层的数据如何拆分,应用只需要连接Mycat即可完成对数据的操作。同时它还支持MySQL、SQL Server、Oracle、DB2、PostgreSQL等主流数据库。但是Mycat不会进行数据存储,它只是用于数据的路由。
其底层是基于拦截思想实现,其会拦截用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
6.2)Mycat特性
支持SQL92标准
遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群。
支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
基于Nio实现,有效管理线程,高并发问题。
支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数。
支持单库内部任意join,支持跨库2表join。
支持通过全局表,ER关系的分片策略,实现了高效的多表join查询。
支持多租户方案。
支持分布式事务(弱xa)。
支持全局序列号,解决分布式下的主键生成问题。
分片规则丰富,插件化开发,易于扩展。
强大的web,命令行监控。
支持前端作为mysq通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 。
支持密码加密
支持服务降级
支持IP白名单
支持SQL黑名单、sql注入攻击拦截
支持分表(1.6)
集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)。
6.3)Mycat源码调试&部署 源码下载: https://codeload.github.com/MyCATApache/Mycat-Server/zip/Mycat-server-1675-release
默认端口:8066
配置启动参数:
-DMYCAT_HOME=D:/workspace/Mycat-Server-Mycat-server-1675-release/src/main #设置堆外内存大小 -XX:MaxDirectMemorySize=512M
为什么要设置堆外内存:当使用mycat对非分片查询时,会把所有的数据查询出来,然后把这部分数据放在堆外内存中
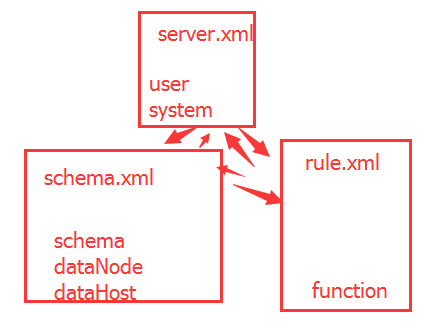
在Mycat有核心三个配置文件,分别为:sever.xml、schema.xml、rule.xml
server.xml :是Mycat服务器参数调整和用户授权的配置文件。schema.xml :是逻辑库定义和表以及分片定义的配置文件rule.xml :是分片规则的配置文件,分片规则的具体一些参数信息单独存放为文件,也在这个目录下,配置文件修改需要重启MyCAT。
6.4)MyCat核心概念 在学习Mycat首先需要先对其内部一些核心概念有足够的了解。
逻辑库 :Mycat中的虚拟数据库。对应实际数据库的概念。在没有使用mycat时,应用需要确定当前连接的数据库等信息,那么当使用mycat后,也需要先虚拟一个数据库,用于应用的连接。逻辑表 :mycat中的虚拟数据表。对应时间数据库中数据表的概念。非分片表 :没有进行数据切分的表。分片表 :已经被数据拆分的表,每个分片表中都有原有数据表的一部分数据。多张分片表可以构成一个完整数据表。ER表 :子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据Join不会跨库操作。表分组(Table Group)是解决跨分片数据join的一种很好的思路,也是数据切分规划的重要一条规则全局表 :可以理解为是一张数据冗余表,如状态表,每一个数据分片节点又保存了一份状态表数据。数据冗余是解决跨分片数据join的一种很好的思路,也是数据切分规划的另外一条重要规则。分片节点(dataNode) :数据切分后,每一个数据分片表所在的数据库就是分片节点。节点主机(dataHost) :数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。分片规则(rule) :按照某种业务规则把数据分到某个分片的规则就是分片规则。全局序列号(sequence) :也可以理解为分布式id。数据切分后,原有的关系数据库中的主键约束在分布式条件下将无法使用,因此需要引入外部机制保证数据唯一性标识,这种保证全局性的数据唯一标识的机制就是全局序列号(sequence),如UUID、雪花算法等。
7)Mycat企业级应用实践 7.1)环境参数配置 在server.xml 文件中的system标签下配置所有的参数,全部为环境参数,可以根据当前需要进行开启和配置,如:设置mycat连接端口号
<property name ="serverPort" > 8066</property >
7.2)数据非分片 7.2.1)配置初始化信息 应用连接mycat的话,也需要设置用户名、密码、被连接数据库信息,要配置这些信息的话,可以修改server.xml,在其内部添加内容如下:
<user name ="mycat" > <property name ="password" > mycat</property > <property name ="schemas" > userdb</property > </user >
7.2.2)配置虚拟数据库&表 当配置了一个虚拟数据库后,还需要修改schema.xml,对虚拟库进行详细配置
<?xml version="1.0" ?> <!DOCTYPE mycat :schema SYSTEM "schema.dtd" > <mycat:schema xmlns:mycat ="http://io.mycat/" > <schema name ="userdb" checkSQLschema ="true" dataNode ="localdn" sqlMaxLimit ="500" > <table name ="tb_user" dataNode ="localdn" primaryKey ="user_id" /> </schema > <dataNode name ="localdn" dataHost ="localdh" database ="user" /> <dataHost balance ="0" maxCon ="100" minCon ="10" name ="localdh" dbType ="mysql" dbDriver ="jdbc" writeType ="0" switchType ="1" slaveThreshold ="1000" > <heartbeat > select user()</heartbeat > <writeHost url ="jdbc:mysql://localhost:3306" host ="host1" password ="root" user ="root" > </writeHost > </dataHost > </mycat:schema >
7.2.3)测试 通过navicat创建本地数据库连接并创建对应数据库,同时创建mycat连接。 在mycat连接中操作表,添加数据,可以发现,本地数据库中同步的也新增了对应的数据。
7.3)根据ID取模数据分片 当一个数据表中的数据量非常大时,就需要考虑对表内数据进行分片,拆分的规则有很多种,比较简单的一种就是,通过对id进行取模,完成数据分片。
1)修改schema.xml
table标签新增属性:subTables、rule
<?xml version="1.0" ?> <!DOCTYPE mycat :schema SYSTEM "schema.dtd" > <mycat:schema xmlns:mycat ="http://io.mycat/" > <schema name ="userdb" checkSQLschema ="true" dataNode ="localdn" sqlMaxLimit ="500" > <table name ="tb_user" dataNode ="localdn" primaryKey ="user_id" subTables ="tb_user$1-3" rule ="mod-long" /> </schema > <dataNode name ="localdn" dataHost ="localdh" database ="user" /> <dataHost balance ="0" maxCon ="100" minCon ="10" name ="localdh" dbType ="mysql" dbDriver ="jdbc" writeType ="0" switchType ="1" slaveThreshold ="1000" > <heartbeat > select user()</heartbeat > <writeHost url ="jdbc:mysql://localhost:3306" host ="host1" password ="root" user ="root" > </writeHost > </dataHost > </mycat:schema >
2)修改rule.xml
在schema.xml中已经指定规则为mod-long。因此需要到该文件中修改对应信息。
<tableRule name ="mod-long" > <rule > <columns > user_id</columns > <algorithm > mod-long</algorithm > </rule > </tableRule > <function name ="mod-long" class ="io.mycat.route.function.PartitionByMod" > <property name ="count" > 3</property > </function >
3)测试
1)向数据库中插入一千条数据,可以发现,其会根据id取模,放入不同的三张表中。
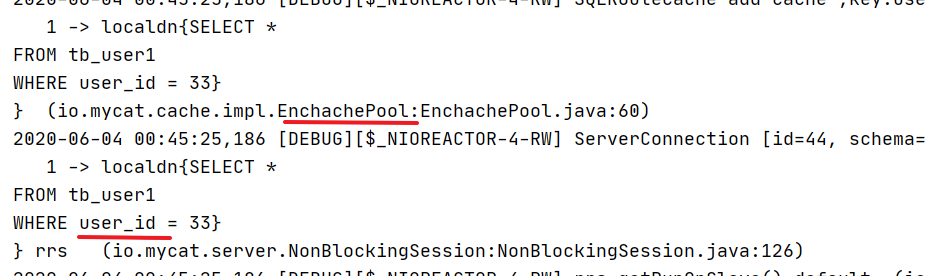
2)当根据id查询时,会通过对id的取模,确定当前要查询的分片。并且首先会先查询mycat中的ehcache缓存,再来查询数据分片
3)当查询所有数据时,会查询所有数据分片。
4)缺陷
通过id取模分片这种方式实际中应用较少。主要因为两点问题:
根据id取模,1)散列不均匀,出现数据倾斜。2)动态扩容时,存在rehash,出现数据丢失。
1)数据散列不均匀,容易出现数据倾斜。每张表中的数据量差距较大。
2)动态扩容后,当需要新增表时,需要对模数修改,有可能就会造成当查询某个分片时,在该分片中找不到对应数据。
3)动态扩容后,要进行rehash操作。
7.4)全局序列号 当进行数据切分后,数据会存放在多张表中,如果仍然通过数据库自增id的方式,就会出现ID重复的问题,造成数据错乱。所以当拆分完数据后,需要让每一条数据都有自己的ID,并且在多表中不能出现重复。比较常见的会使用雪花算法来生成分布式id。
在Mycat中也提供了四种方式来进行分布式id生成:基于文件、基于数据库、基于时间戳和基于ZK。
7.4.1)基于本地文件方式生成 优点:本地加载,读取速度较快。
缺点:当MyCAT重新发布后,配置文件中的sequence会恢复到初始值。
生成的id没有含义,如时间。
MyCat如果存在多个,会出现id重复问题。
1)修改sequence_conf.properties
USER.HISIDS = #使用过的历史分段,可不配置 USER.MINID =1 #最小ID值 USER.MAXID =200000 #最大ID值 USER.CURID =1000 #当前ID值
2)修改server.xml
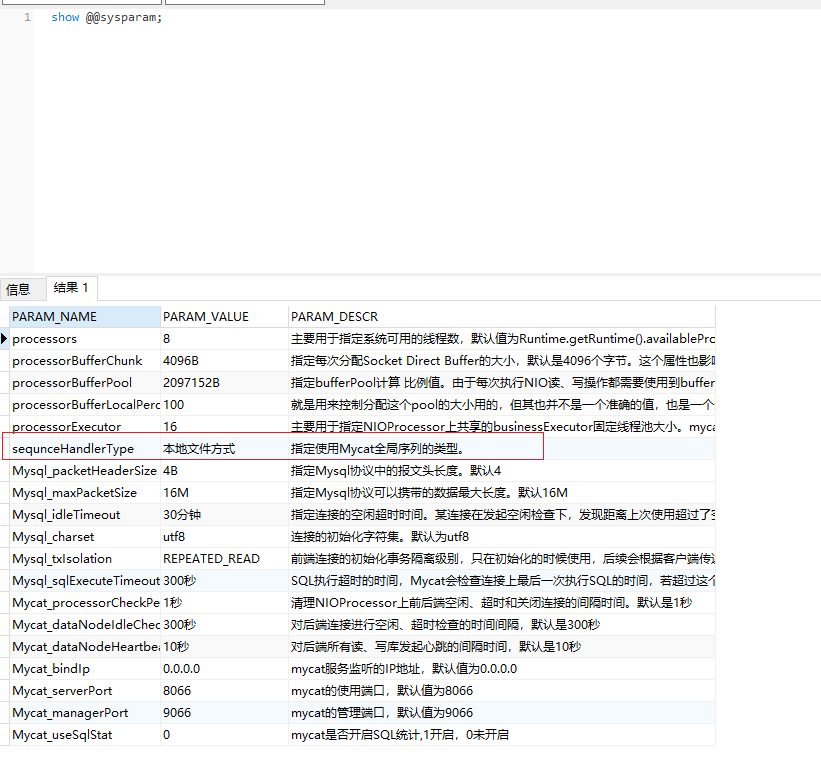
<property name ="sequnceHandlerType" > 0</property > <property name ="sequnceHandlerPattern" > (?:(/s*next/s+value/s+for/s*MYCATSEQ_(/w+))(,|/)|/s)*)+</property > <property name ="sequenceHanlderClass" > io.mycat.route.sequence.handler.HttpIncrSequenceHandler</property >
3)测试
重启mycat,并查询是否修改成功
通过navicat插入数据
insert into tb_user(user_id,user_name) values ('next value for MYCATSEQ_USER' ,'wangwu' )
通过程序插入数据
@Insert("insert into tb_user(user_id,user_name) values('next value for MYCATSEQ_USER',#{userName})") void addUser (User user) ;
7.4.2)基于数据库生成 优点:能够进行id批量生成,在分布式下,可以避免id重复问题。
缺点:ID没有意义,对数据库有压力。
1)在实际数据库执行dbseq.sql中的sql语句 ,执行完毕后,会创建一张表。
2)修改sequence_db_conf.properties 。
3)修改server.xml文件 ,修改全局序列号生成方式为数据库方式
<property name ="sequnceHandlerType" > 1</property >
4)修改schema.xml。在table中添加自增属性
<table name ="tb_user" dataNode ="localdn" primaryKey ="id" subTables ="tb_user$1-3" rule ="mod-long" autoIncrement ="true" />
5)测试
通过navicat新增记录
insert into tb_user(user_id,user_name) values ('next value for MYCATSEQ_TB_USER' ,'wangwu' )
7.4.3)基于zookeeper生成 1)修改server.xml ,更改生成模式
<property name ="sequenceHandlerType" > 3</property >
2)修改myid.properties ,配置zk连接信息
loadZk =true zkURL =192.168.200.131:2181 clusterId =01 myid =mycat_fz_01 clusterNodes =mycat_fz_01
3)修改sequence_distributed_conf.properties
INSTANCEID=ZK #声明使用zk生成 CLUSTERID=01
4)测试
启动mycatServer后,通过zk客户端查看节点信息。会发现新增了一个mycat节点
插入数据
insert into tb_user(user_id,user_name) values ('next value for MYCATSEQ_TB_USER12' ,'heima' )
next value for MYCATSEQ_ 后的内容可以随意指定。
5)特性:
ID 结构:long 64 位 ,ID 最大可占 63 位
/* |current time millis(微秒时间戳 38 位,可以使用 17 年)|clusterId(机房或者 ZKid,通过配置文件配置 5位)|instanceId(实例 ID,可以通过 ZK 或者配置文件获取,5 位)|threadId(线程 ID,9 位)|increment(自增,6 位)
/* 一共 63 位,可以承受单机房单机器单线程 1000*(2^6)=640000 的并发。
/* 无悲观锁,无强竞争,吞吐量更高
7.4.4)基于时间戳生成 优点:不存在上面两种方案因为mycat的重启导致id重复的现象
ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加),每毫秒可以并发 12 位二进制的累加。
缺点:数据类型太长,建议采用bigint(最大取值18446744073709551615)
1)修改server.xml 。更改生成方式
<property name ="sequenceHandlerType" > 2</property >
2)修改sequence_time_conf.properties
WORKID =01 DATAACENTERID =01
3)测试
新增数据
insert into tb_user(user_id,user_name) values('next value for MYCATSEQ_TB_USER12','heima')
next value for MYCATSEQ_ 后的内容可以随意指定。
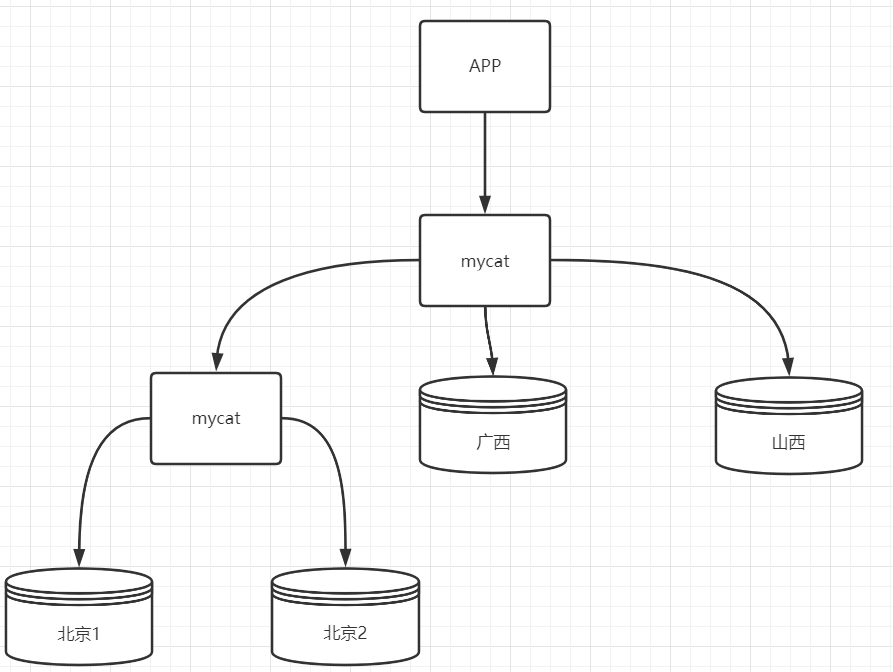
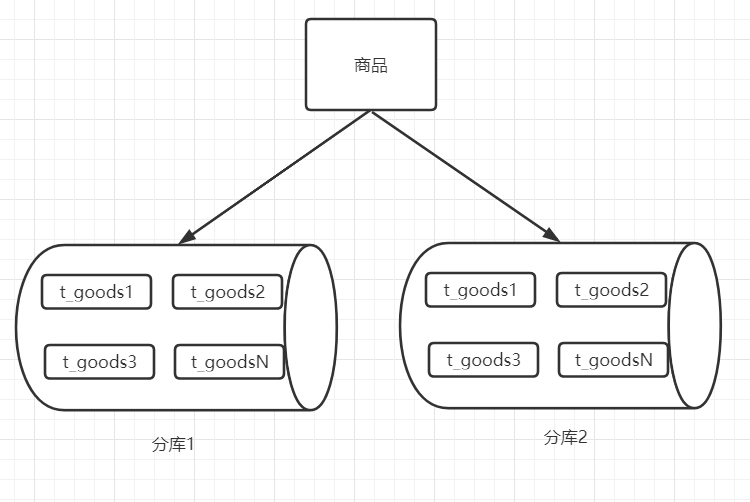
7.5)Mycat分库&读写分离 之前已经基于id取模完成了分表操作,但是一个数据库的容量毕竟是有限制的,如果数据量非常大,分表已经满足不了的话,就会进行分库操作。
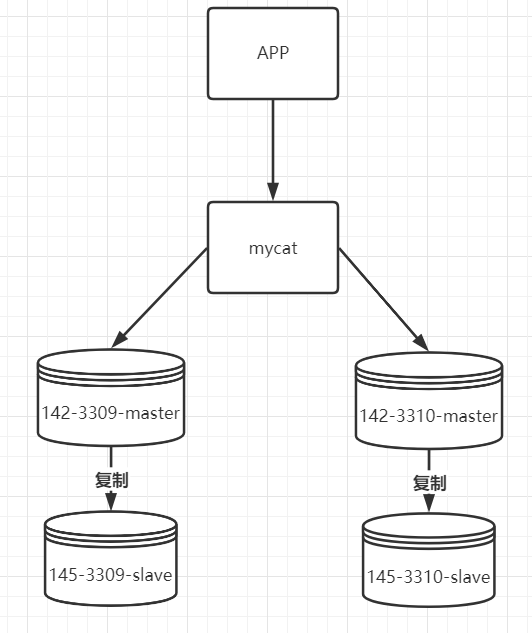
当前分库架构如下:
现在存在两个主库,并且各自都有从节点。 当插入数据时,根据id取模放入不同的库中。同时主从间在进行写时复制的同时,还要完成主从读写分离的配置。
1)修改schema.xml。配置多datenode与datahost。同时配置主从读写分离。
<?xml version="1.0" ?> <!DOCTYPE mycat :schema SYSTEM "schema.dtd" > <mycat:schema xmlns:mycat ="http://io.mycat/" > <schema name ="userdb" checkSQLschema ="true" dataNode ="dn09" sqlMaxLimit ="500" > <table name ="tb_user" dataNode ="dn09,dn10" primaryKey ="user_id" rule ="mod-long" /> </schema > <dataNode name ="dn09" dataHost ="dh09" database ="user" /> <dataNode name ="dn10" dataHost ="dh10" database ="user" /> <dataHost name ="dh09" balance ="1" maxCon ="100" minCon ="10" dbType ="mysql" dbDriver ="jdbc" writeType ="0" switchType ="1" slaveThreshold ="1000" > <heartbeat > select user()</heartbeat > <writeHost url ="jdbc:mysql://192.168.200.142:3309" host ="host1" user ="root" password ="123456" > <readHost host ="host2" url ="jdbc:mysql://192.168.200.145:3309" user ="root" password ="123456" > </readHost > </writeHost > </dataHost > <dataHost name ="dh10" balance ="1" maxCon ="100" minCon ="10" dbType ="mysql" dbDriver ="jdbc" writeType ="0" switchType ="1" slaveThreshold ="1000" > <heartbeat > select user()</heartbeat > <writeHost url ="jdbc:mysql://192.168.200.142:3310" host ="host1" user ="root" password ="123456" > <readHost host ="host2" url ="jdbc:mysql://192.168.200.145:3310" user ="root" password ="123456" > </readHost > </writeHost > </dataHost > </mycat:schema >
2)修改rule.xml。配置取模时的模数
<function name ="mod-long" class ="io.mycat.route.function.PartitionByMod" > <property name ="count" > 2</property > </function >
3)进行批量数据添加,可以发现数据落在了不同的库中。
4)读写分离验证
设置log4j2.xml的日志级别为DEBUG
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status ="DEBUG" > ........ <asyncRoot level ="DEBUG" includeLocation ="true" > ........ </asyncRoot > </Loggers > </Configuration >
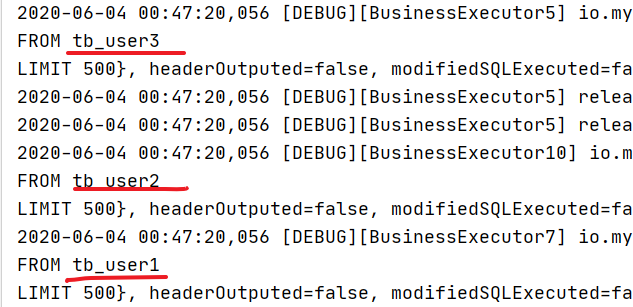
基于mysql服务进行数据查看,观察控制台信息,可以看到对于read请求的数据源,分别使用的是配置文件的配置
7.6)MyCat分片规则 7.6.1)枚举分片 7.6.1.1)实现 适用于在特定业务场景下,将不同的数据存放于不同的数据库中,如按省份、按人员信息等。
1)修改schema.xml ,修改table 标签中name 属性为当前操作的表名,rule 属性为sharding-by-intfile
<table name ="tb_user_sharding_by_intfile" dataNode ="dn142,dn145" primaryKey ="user_id" rule ="sharding-by-intfile" />
2)修改rule.xml ,配置tableRule 为sharding-by-intfile 中columns 属性为当前指定分片字段
<tableRule name ="sharding-by-intfile" > <rule > <columns > sex</columns > <algorithm > hash-int</algorithm > </rule > </tableRule >
3)修改rule.xml 中hash-int
<function name ="hash-int" class ="io.mycat.route.function.PartitionByFileMap" > <property name ="mapFile" > partition-hash-int.txt</property > <property name ="type" > 1</property > <property name ="defaultNode" > 0</property > </function >
4)修改partition-hash-int.txt 。指定分片字段不同值存在于不同的数据库节点
male=0 #代表第一个datanode female=1 #代表第二个datanode
5)执行测试
修改mapper
@Insert("insert into tb_user_sharding_by_intfile(user_id,user_name,sex) values('next value for MYCATSEQ_TB_USER12',#{userName},#{sex})") void addUserShareBySex (User user) ;
执行测试,此时可以发现,当sex为male时,数据会进入142节点,当sex为female时,数据会进入145节点。
7.6.1.2)问题 该方案适用于特定业务场景进行数据分片,但该方式容易出现数据倾斜,如不同省份的订单量一定会不同。订单量大的省份还会进行数据分库,数据库架构就会继续发生对应改变。
7.6.2)固定hash分片 固定hash分片的工作原理类似与redis cluster槽的概念,在固定hash中会有一个范围是0-1024,内部会进行二进制运算操作,如取 id 的二进制低 10 位 与 1111111111 进行 & 运算。从而当出现连接数据插入,其有可能会进入到同一个分片中,减少了分布式事务操作,提升插入效率同时尽量减少了数据倾斜问题,但不能避免不出现数据倾斜。
按照上面这张图就存在两个分区,partition1和partition2。partition1的范围是0-255,partition2的范围是256-1024。
当向分区中存数据时,先将id值转换为二进制,接着&1111111111,再对结果值转换为十进制,从而确定当前数据应该存入哪个分区中。
1023的二进制&1111111111运算后为1023,故落入第二个分区
1024的二进制&1111111111运算后为0,故落入第一个分区
266 的二进制&1111111111运算后为266,故落入第二个分区内
7.6.2.1)实现 1)修改schema.xml ,配置自定义固定hash分配规则
<table name ="tb_user_fixed_hash" dataNode ="dn142,dn145" primaryKey ="user_id" rule ="partition-by-fixed-hash" />
2)修改rule.xml ,配置自定义固定hash分片规则
<tableRule name ="partition-by-fixed-hash" > <rule > <columns > user_id</columns > <algorithm > partition-by-fixed-hash</algorithm > </rule > </tableRule > <function name ="partition-by-fixed-hash" class ="io.mycat.route.function.PartitionByLong" > <property name ="partitionCount" > 1,1</property > <property name ="partitionLength" > 256,768</property > </function >
3)测试,添加数据,可以发现数据会根据计算,落入相应的数据库节点。
7.6.3)固定范围分片 该规则有点像枚举与固定hash的综合体,设置某一个字段,然后规定该字段值的不同范围值会进入到哪一个dataNode。适用于明确知道分片字段的某个范围属于某个分片
优点:适用于想明确知道某个分片字段的某个范围具体在哪一个节点;
缺点:如果短时间内有大量的批量插入操作,那么某个分片节点可能一下子会承受比较大的数据库压力,而别的分片节点此时可能处于闲置状态,无法利用其它节点进行分担压力(热点数据问题);
1)修改schema.xml 。
<table name ="tb_user_range" dataNode ="dn142,dn145" primaryKey ="user_id" rule ="auto-sharding-long" />
2)修改rule.xml
<tableRule name ="auto-sharding-long" > <rule > <columns > age</columns > <algorithm > rang-long</algorithm > </rule > </tableRule >
3)修改autopartition-long.txt ,定义自定义范围
#用于定义dataNode对应的数据范围,如果配置多了会报错。 # range start-end ,data node index # K=1000,M=10000. #0-500M=0 #500M-1000M=1 #1000M-1500M=2 #所有的节点配置都是从0开始,0代表节点1 0-20=0 21-50=1
4)测试,添加用户信息,年龄分别为9和33,可以看到,数据落入到对应的数据节点
7.6.4)取模范围分片 这种方式结合了范围分片和取模分片,主要是为后续的数据迁移做准备。
优点:可以自主决定取模后数据的节点分布。
缺点:dataNode 划分节点是事先建好的,需要扩展时比较麻烦。
1)修改schema.xml,配置分片规则
<table name ="tb_user_mod_range" dataNode ="dn142,dn145" primaryKey ="user_id" rule ="sharding-by-partition" />
2)修改rule.xml,添加分片规则
<tableRule name ="sharding-by-partition" > <rule > <columns > user_id</columns > <algorithm > sharding-by-partition</algorithm > </rule > </tableRule > <function name ="sharding-by-partition" class ="io.mycat.route.function.PartitionByPattern" > <property name ="patternValue" > 256</property > <property name ="defaultNode" > 0</property > <property name ="mapFile" > partition-pattern.txt</property > </function >
3)添加partition-pattern.txt,文件内部配置节点中数据范围
#0-128表示id%256后的数据范围。 0-128=0 129-256=1
4)测试
可以发现数据根据id取模并进入到了不同的分片节点中。
7.6.5)字符串hash求模范围分片 在业务场景下,有时可能会根据某个分片字段的前几个值来进行取模。如地址信息只取省份、姓名只取前一个字的姓等。此时则可以使用该种方式。
其工作方式与取模范围分片类型,该分片方式支持数值、符号、字母取模。
1)修改schema.xml。
<table name ="tb_user_string_hash" dataNode ="dn142,dn145" primaryKey ="user_id" rule ="sharding-by-string-hash" />
2)修改rule.xml,定义拆分规则
<tableRule name ="sharding-by-string-hash" > <rule > <columns > user_name</columns > <algorithm > sharding-by-string-hash-function</algorithm > </rule > </tableRule > <function name ="sharding-by-string-hash-function" class ="io.mycat.route.function.PartitionByPrefixPattern" > <property name ="patternValue" > 256</property > <property name ="prefixLength" > 1</property > <property name ="mapFile" > partition-pattern-string-hash.txt</property > </function >
3)新建partition-pattern-string-hash.txt。指定数据分片节点
4)运行后可以发现 ,不同的姓名取模后,会进入不同的分片节点。
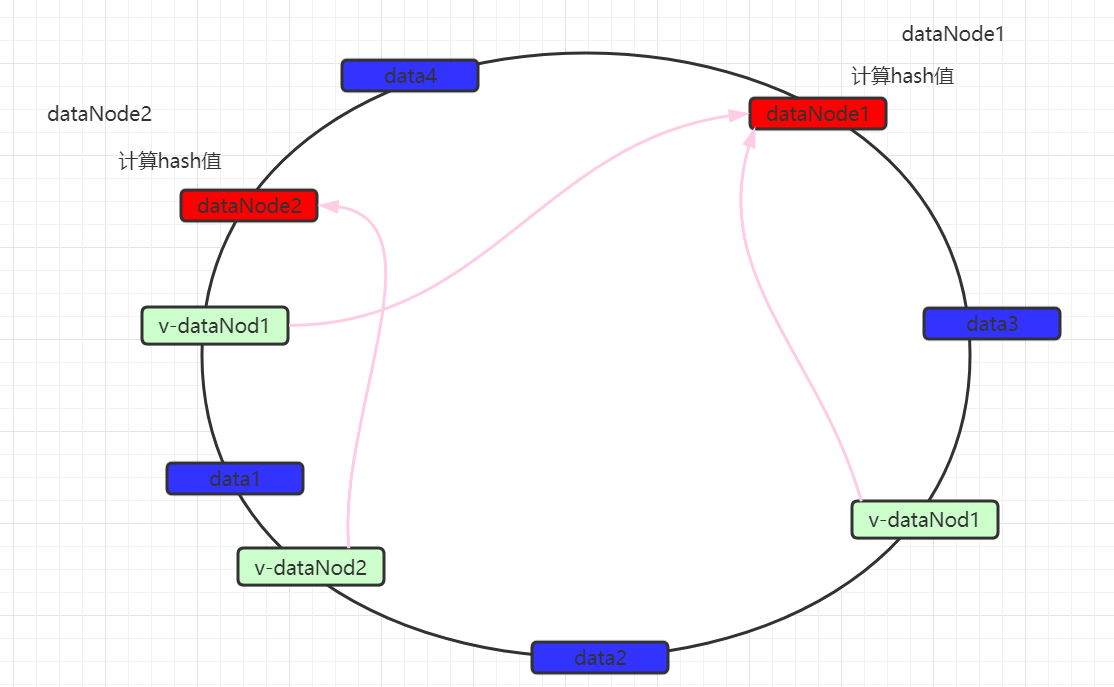
7.6.6)一致性hash分片 通过一致性hash分片可以最大限度的让数据均匀分布,但是均匀分布也会带来问题,就是分布式事务。
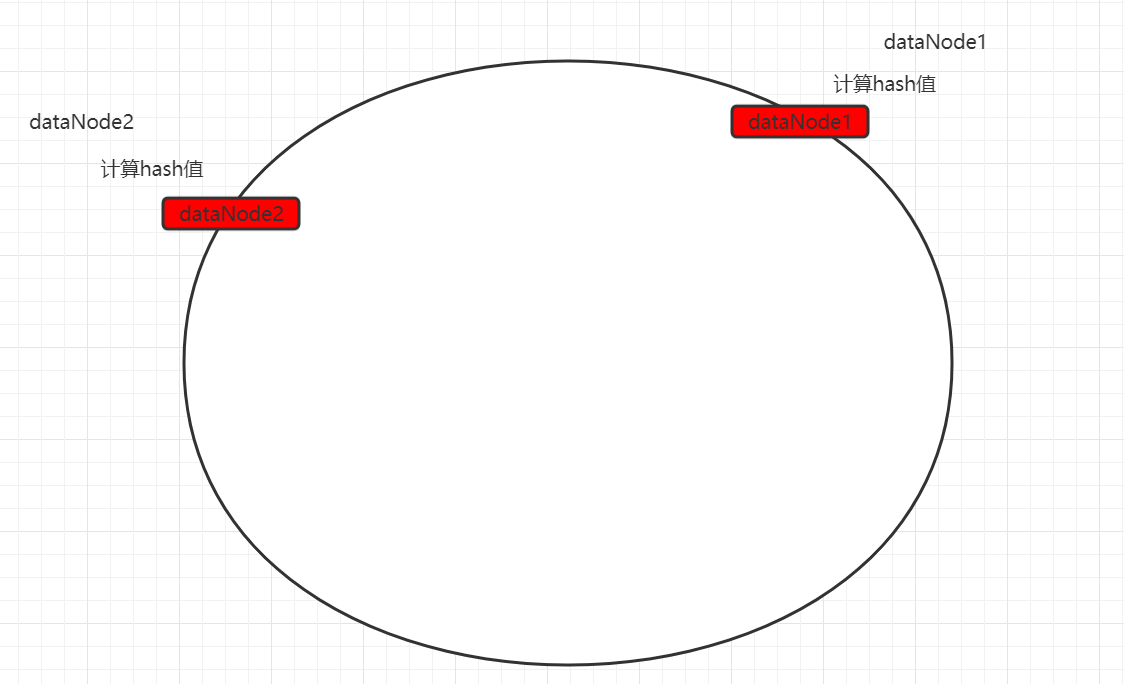
7.6.6.1)原理 一致性hash算法引入了hash环的概念。环的大小是0~2^32-1。首先通过crc16算法计算出数据节点在hash环中的位置。
当存储数据时,也会采用同样的算法,计算出数据key的hash值,映射到hash环上。
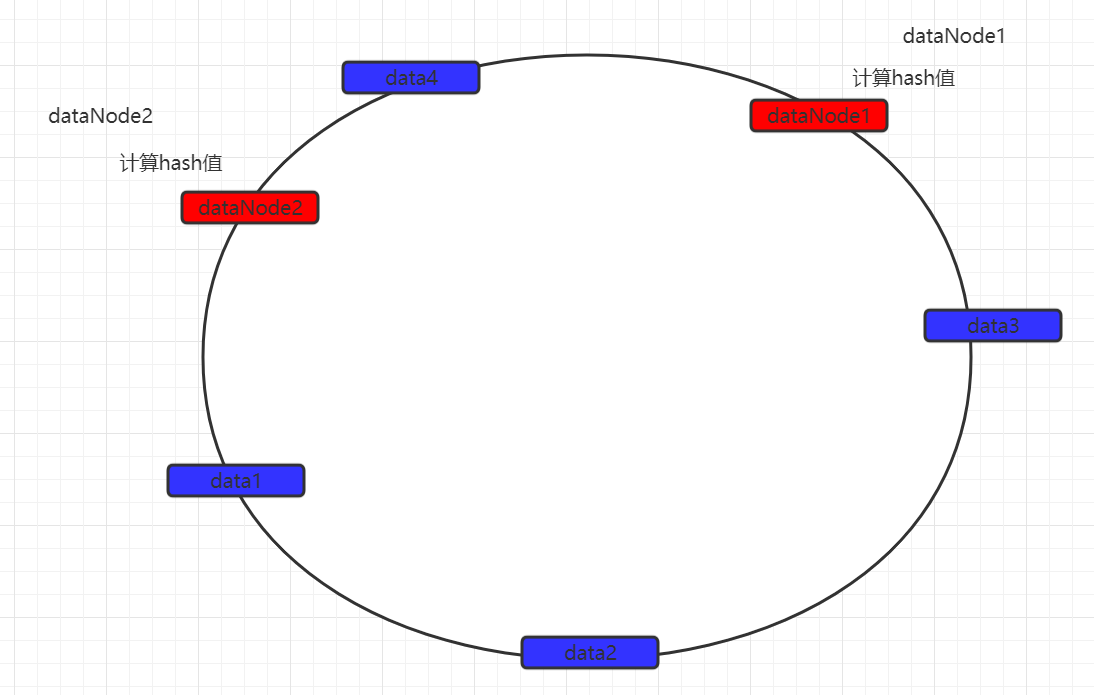
然后从数据映射的位置开始,以顺时针的方式找出距离最近的数据节点,接着将数据存入到该节点中。
此时可以发现,数据并没有达到预期的数据均匀,可以发现如果两个数据节点在环上的距离,决定有大量数据存入了dataNode2,而仅有少量数据存入dataNode1。
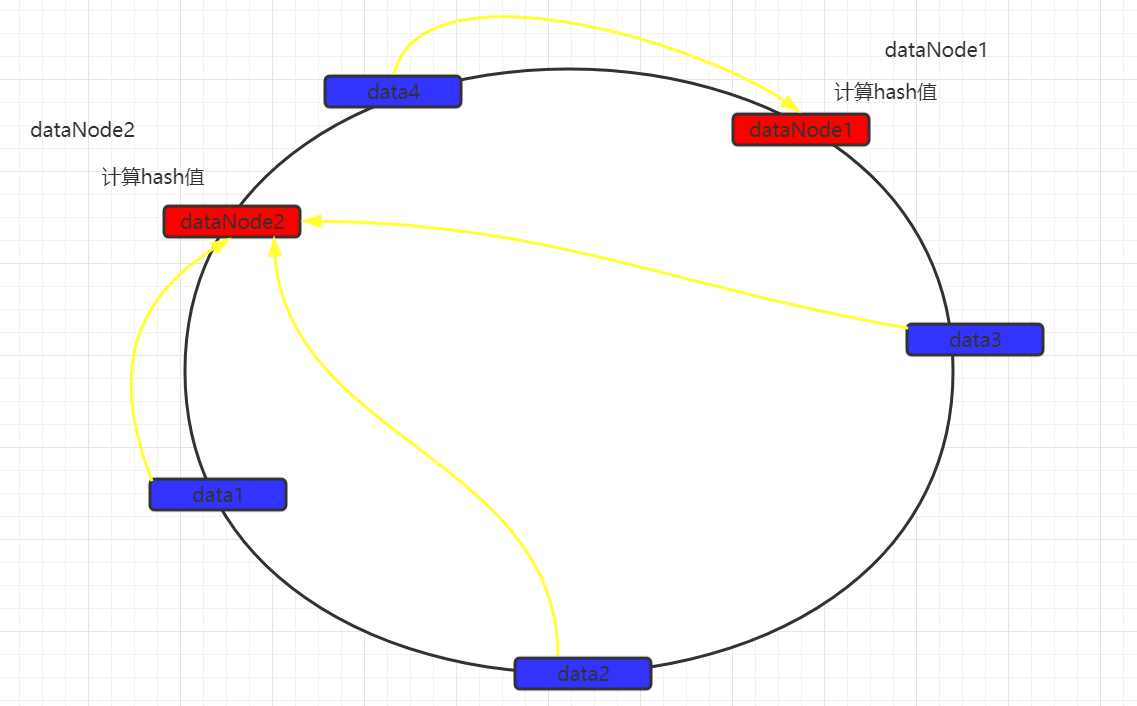
为了解决数据不均匀的问题,在mycat中可以设置虚拟数据映射节点 。同时这些虚拟节点会映射到实际数据节点。
数据仍然以顺时针方式寻找数据节点,当找到最近的数据节点无论是实际还是虚拟,都会进行存储,如果是虚拟数据节点的话,最终会将数据保存到实际数据节点中。 从而尽量的使数据均匀分布。
7.6.6.2)实现 1)修改schema.xml
<table name ="tb_user_murmur" dataNode ="dn142,dn145" primaryKey ="user_id" rule ="sharding-by-murmur" />
2)修改rule.xml
<tableRule name ="sharding-by-murmur" > <rule > <columns > user_id</columns > <algorithm > murmur</algorithm > </rule > </tableRule > <function name ="murmur" class ="io.mycat.route.function.PartitionByMurmurHash" > <property name ="seed" > 0</property > <property name ="count" > 2</property > <property name ="virtualBucketTimes" > 160</property > </function >
3)测试
循环插入一千条数据,可以数据会尽量均匀的分布在142和145两个节点中。
7.6.7)时间分片 7.6.7.1)按天分片 当数据量非常大时,有时会考虑,按天去分库分表。这种场景是非常常见的。同时也有利于后期的数据查询。
1)修改schema.xml
<table name ="tb_user_day" dataNode ="dn142,dn145" primaryKey ="user_id" rule ="sharding-by-date" />
2)修改rule.xml,每十天一个分片,从起始时间开始计算,分片不够,则报错。
<tableRule name ="sharding-by-date" > <rule > <columns > create_time</columns > <algorithm > partbyday</algorithm > </rule > </tableRule > <function name ="partbyday" class ="io.mycat.route.function.PartitionByDate" > <property name ="dateFormat" > yyyy-MM-dd</property > <property name ="sNaturalDay" > 0</property > <property name ="sBeginDate" > 2020-01-01</property > <property name ="sPartionDay" > 10</property > </function >
3)测试
@Test public void addUserDay () { User user = new User (); user.setUserName("lisi" ); user.setCreateTime("2020-01-31" ); userMapper.addUserDay(user); }
当时间为1月1-10号之间,会进入142节点。当时间为11-20号之间,会进入145节点,当超出则报错。
7.6.7.2)按月分片 按月进行数据分片,每月一个分片
1)修改schema.xml
<table name ="tb_user_month" dataNode ="dn142,dn145" primaryKey ="user_id" rule ="sharding-by-month" />
2)修改rule.xml
<tableRule name ="sharding-by-month" > <rule > <columns > create_time</columns > <algorithm > sharding-by-month-function</algorithm > </rule > </tableRule > <function name ="sharding-by-month-function" class ="io.mycat.route.function.PartitionByMonth" > <property name ="dateFormat" > yyyy-MM-dd</property > <property name ="sBeginDate" > 2020-05-01</property > </function >
3)测试
可以发现当为五月会进入到节点1中,当为六月会进入到节点2中。当为七月则报错,因为需要每月一个分片,当前测试只有两个分片。
7.7)跨库join 7.7.1)全局表 7.7.1.1)简介 系统中基本都会存在数据字典信息,如数据分类信息、项目的配置信息等。这些字典数据最大的特点就是数据量不大并且很少会被改变。同时绝大多数的业务场景都会涉及到字典表的操作。 因此为了避免频繁的跨库join操作,结合冗余数据思想,可以考虑把这些字典信息在每一个分库中都存在一份。
mycat在进行join操作时,当业务表与全局表进行聚合会优先选择相同分片的全局表,从而避免跨库join操作。在进行数据插入时,会把数据同时插入到所有分片的全局表中。
7.7.1.2)实现 1)修改schema.xml
<table name ="tb_global" dataNode ="dn142,dn145" primaryKey ="global_id" type ="global" />
2)测试,可以发现会同时向两张表中插入数据
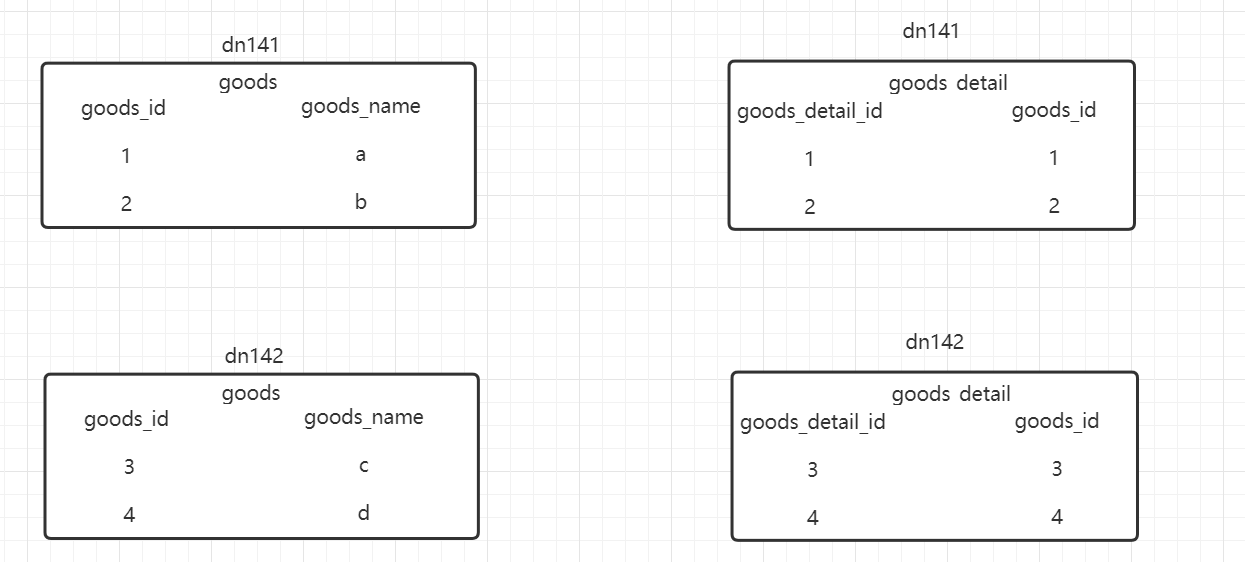
7.7.2)ER表 7.7.2.1)介绍 ER表也是一种为了避免跨库join的手段,在业务开发时,经常会使用到主从表关系的查询,如商品表与商品详情表。
根据上图就是一个简单的表关系,但是现在有可能出现一个问题:goods_detail中goods_id为1,2这两条数据有可能存在于142中 。这样就造成了跨库join的问题的。并且在不使用ER表的情况下,还有可能出现数据丢失的问题。
ER表的出现就是为了让有关系的表数据存储于同一个分片中,从而避免跨库join的出现。
7.7.2.2)不使用ER表问题演示 1)修改schema.xml,配置商品与商品详情表信息
<table name ="tb_goods" dataNode ="dn142,dn145" primaryKey ="goods_id" rule ="sharding-by-murmur-goods" /> <table name ="tb_goods_detail" dataNode ="dn142,dn145" primaryKey ="goods_detail_id" rule ="sharding-by-murmur-goods-detail" />
2)修改rule.xml
<tableRule name ="sharding-by-murmur-goods" > <rule > <columns > goods_id</columns > <algorithm > murmur</algorithm > </rule > </tableRule > <tableRule name ="sharding-by-murmur-goods-detail" > <rule > <columns > goods_detail_id</columns > <algorithm > murmur</algorithm > </rule > </tableRule >
3)插入数据,不要使用自动生成id。
@Autowired private IdWorker idWorker;@Test public void addGoodsInfo () { for (int i = 1 ; i <= 1000 ; i++) { Goods goods = new Goods (); long goodsId = idWorker.nextId(); goods.setGoodsId(goodsId); goods.setGoodsName("heima" +i); goodsMapper.addGoods(goods); GoodsDetail goodsDetail = new GoodsDetail (); goodsDetail.setGoodsDetailId(idWorker.nextId()); goodsDetail.setGoodsId(goodsId); goodsDetail.setGoodsDetailName("heima goodsDetail" +i); goodsDetailMapper.addGoodsDetail(goodsDetail); } }
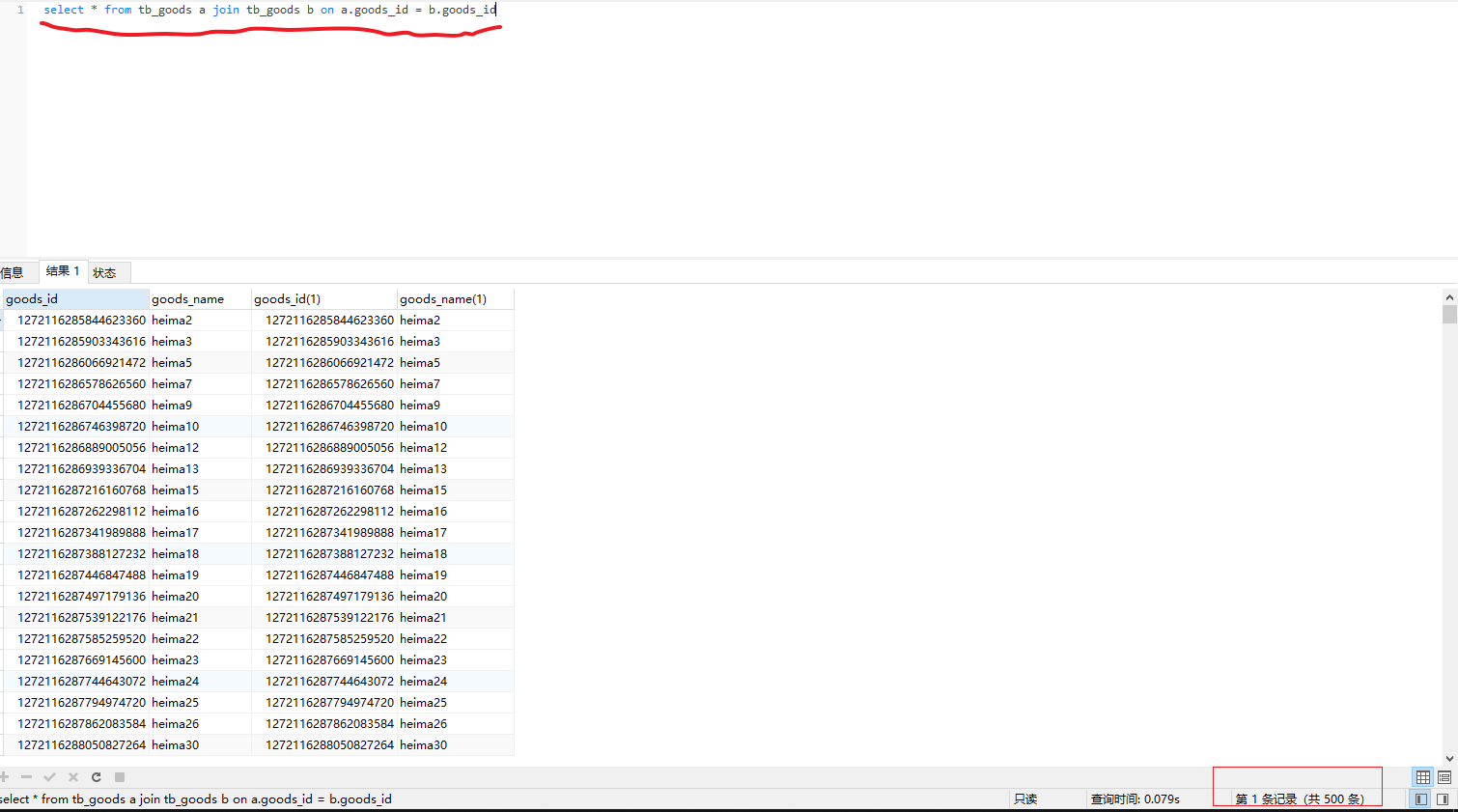
4)连接mycat查询数据,可以发现出现数据丢失。
select * from tb_goods a join tb_goods_detail b on a.goods_id = b.goods_id
7.7.2.3)ER实现 1)修改schema.xml。配置er表
<table name ="tb_goods" dataNode ="dn142,dn145" primaryKey ="goods_id" rule ="sharding-by-murmur-goods" > <childTable name ="tb_goods_detail" primaryKey ="goods_detail_id" joinKey ="goods_id" parentKey ="goods_id" > </childTable > </table >
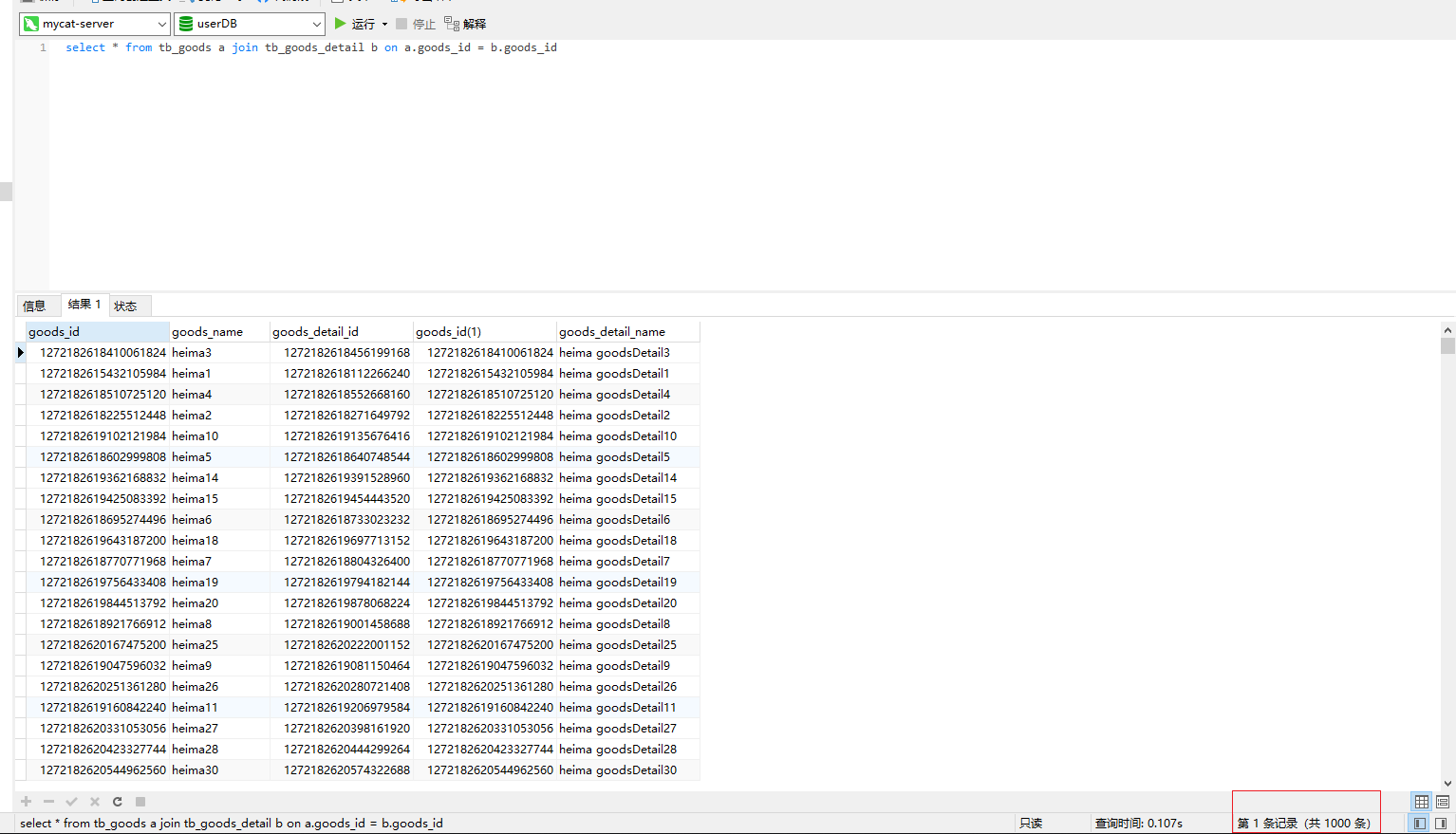
2)测试
删除原有数据,并重新插入数据,此时再次join查询,可以发现全部的一千条数据都已经获取到了。同时有关联关系的数据,也都存在于同一个数据分片中。
8)Mycat企业级架构设计&应用 8.1)Mycat主从切换 基于Mycat主从复制方案,当前存在一个主节点和一个从节点,主节点负责写操作,从节点负责读操作。当在一个dataHost中配置了两个或多个writeHost,如果第一个writeHost宕机,则Mycat会在默认3次心跳检查失败后,自动切换到下一个可用的writeHost执行DML语句,并在conf/dnindex.properties 文件里记录当前所用的writeHost的index。
在Mycat主从切换中,可以将从节点也配置为是一个写节点(相当于从节点同时负责读写)。当原有的master写节点宕机后,从节点会被提升为主节点,同时负责读写操作。当写节点恢复后,会被作为从节点使用,保持现有状态不变,跟随新的主节点。
简单点说就是:原来的主变成从,原来的从一直为主。
8.1.1)修改schema.xml <?xml version="1.0" ?> <!DOCTYPE mycat :schema SYSTEM "schema.dtd" > <mycat:schema xmlns:mycat ="http://io.mycat/" > <schema name ="userdb" checkSQLschema ="true" dataNode ="dn142" sqlMaxLimit ="500" > <table name ="tb_user" dataNode ="dn142" primaryKey ="user_id" /> </schema > <dataNode name ="dn142" dataHost ="dh142" database ="user" /> <dataHost name ="dh142" writeType ="0" balance ="1" switchType ="1" maxCon ="100" minCon ="10" dbType ="mysql" dbDriver ="jdbc" slaveThreshold ="1000" > <heartbeat > show slave status</heartbeat > <writeHost url ="jdbc:mysql://192.168.200.142:3309" host ="host1" user ="root" password ="123456" > <readHost host ="host2" url ="jdbc:mysql://192.168.200.145:3309" user ="root" password ="123456" > </readHost > </writeHost > <writeHost url ="jdbc:mysql://192.168.200.145:3309" host ="host2" user ="root" password ="123456" > </writeHost > </dataHost > </mycat:schema >
8.1.2)测试 开始测试时,当前host1为master写节点,host2为slave读节点同时作为备用写节点。
1)查看conf/dnindex.properties。可以发现dn142的值0,代表为第一个写节点。
2)向tb_user表中插入数据。期望效果:当前host1为写节点,数据会进入到host1中,并复制到host2中
insert into tb_user(user_name) values ('zhangsan' );
3)停止host1的mysql服务。并重新执行添加操作。
insert into tb_user(user_name) values ('lisi' )
此时mycat Server控制台信息
同时查看conf/dnindex.properties。可以发现dn142的值已从0变为1。进行了节点更改。
数据可以插入成功,但是数据会进入到第二个写节点中
4)重启host1服务。并重新插入数据。
insert into tb_user(user_name) values ('wangwu' )
此时可以发现数据仍然会进入到host2中,因为就算之前的host1恢复了,根据mycat的规则其也不会自动提升为写节点,因此写节点仍然为host2。
并且当前为主从架构,并没有配置为双向复制。所以数据进入到host2后,host1中仍然没有数据,符合预期。此时host2会同时负责读、写请求。
8.2)动态扩容&数据迁移 在生产环境下,当原有的数据库节点已经满足不了当前的数据存储量,此时就会在现有数据库基础上新增数据节点。但是当新增数据节点后,就要考虑原有的数据应该如何迁移一部分数据到新增的数据节点上。
1)上传mycat,并在mycat目录下创建logs目录,并在logs目录中创建mycat.pid文件
1)/conf目录下新建newSchema.xml和newRule.xml,用于配置扩容节点。修改内容如下
<?xml version="1.0" ?> <!DOCTYPE mycat :schema SYSTEM "schema.dtd" > <mycat:schema xmlns:mycat ="http://io.mycat/" > <schema name ="userdb" checkSQLschema ="true" dataNode ="dn180" sqlMaxLimit ="500" > <table name ="tb_user" dataNode ="dn180,dn181,dn182" primaryKey ="user_id" rule ="mod-long" > </table > </schema > <dataNode name ="dn180" dataHost ="dh180" database ="user" /> <dataNode name ="dn181" dataHost ="dh181" database ="user" /> <dataNode name ="dn182" dataHost ="dh182" database ="user" /> <dataHost name ="dh180" balance ="0" maxCon ="100" minCon ="10" dbType ="mysql" dbDriver ="jdbc" writeType ="0" switchType ="1" slaveThreshold ="1000" > <heartbeat > select user()</heartbeat > <writeHost url ="jdbc:mysql://192.168.200.180:3311" host ="host1" user ="root" password ="123456" > </writeHost > </dataHost > <dataHost name ="dh181" balance ="0" maxCon ="100" minCon ="10" dbType ="mysql" dbDriver ="jdbc" writeType ="0" switchType ="1" slaveThreshold ="1000" > <heartbeat > select user()</heartbeat > <writeHost url ="jdbc:mysql://192.168.200.181:3311" host ="host1" user ="root" password ="123456" > </writeHost > </dataHost > <dataHost name ="dh182" balance ="0" maxCon ="100" minCon ="10" dbType ="mysql" dbDriver ="jdbc" writeType ="0" switchType ="1" slaveThreshold ="1000" > <heartbeat > select user()</heartbeat > <writeHost url ="jdbc:mysql://192.168.200.182:3311" host ="host1" user ="root" password ="123456" > </writeHost > </dataHost > </mycat:schema >
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mycat :rule SYSTEM "rule.dtd" > <mycat:rule xmlns:mycat ="http://io.mycat/" > <tableRule name ="rule1" > <rule > <columns > id</columns > <algorithm > func1</algorithm > </rule > </tableRule > <tableRule name ="partition-by-fixed-hash" > <rule > <columns > user_id</columns > <algorithm > partition-by-fixed-hash</algorithm > </rule > </tableRule > <tableRule name ="sharding-by-date" > <rule > <columns > create_time</columns > <algorithm > partbyday</algorithm > </rule > </tableRule > <tableRule name ="rule2" > <rule > <columns > user_id</columns > <algorithm > func1</algorithm > </rule > </tableRule > <tableRule name ="sharding-by-intfile" > <rule > <columns > sex</columns > <algorithm > hash-int</algorithm > </rule > </tableRule > <tableRule name ="auto-sharding-long" > <rule > <columns > age</columns > <algorithm > rang-long</algorithm > </rule > </tableRule > <tableRule name ="mod-long" > <rule > <columns > user_id</columns > <algorithm > mod-long</algorithm > </rule > </tableRule > <tableRule name ="sharding-by-murmur" > <rule > <columns > user_id</columns > <algorithm > murmur</algorithm > </rule > </tableRule > <tableRule name ="sharding-by-murmur-goods" > <rule > <columns > goods_id</columns > <algorithm > murmur</algorithm > </rule > </tableRule > <tableRule name ="sharding-by-murmur-goods-detail" > <rule > <columns > goods_detail_id</columns > <algorithm > murmur</algorithm > </rule > </tableRule > <tableRule name ="crc32slot" > <rule > <columns > id</columns > <algorithm > crc32slot</algorithm > </rule > </tableRule > <tableRule name ="sharding-by-month" > <rule > <columns > create_time</columns > <algorithm > sharding-by-month-function</algorithm > </rule > </tableRule > <tableRule name ="latest-month-calldate" > <rule > <columns > calldate</columns > <algorithm > latestMonth</algorithm > </rule > </tableRule > <tableRule name ="auto-sharding-rang-mod" > <rule > <columns > id</columns > <algorithm > rang-mod</algorithm > </rule > </tableRule > <tableRule name ="jch" > <rule > <columns > id</columns > <algorithm > jump-consistent-hash</algorithm > </rule > </tableRule > <tableRule name ="sharding-by-hour" > <rule > <columns > user_hour</columns > <algorithm > sharding-by-hour-function</algorithm > </rule > </tableRule > <function name ="murmur" class ="io.mycat.route.function.PartitionByMurmurHash" > <property name ="seed" > 0</property > <property name ="count" > 2</property > <property name ="virtualBucketTimes" > 160</property > </function > <function name ="crc32slot" class ="io.mycat.route.function.PartitionByCRC32PreSlot" > <property name ="count" > 2</property > </function > <function name ="hash-int" class ="io.mycat.route.function.PartitionByFileMap" > <property name ="mapFile" > partition-hash-int.txt</property > <property name ="type" > 1</property > <property name ="defaultNode" > 0</property > </function > <function name ="rang-long" class ="io.mycat.route.function.AutoPartitionByLong" > <property name ="mapFile" > autopartition-long.txt</property > </function > <function name ="mod-long" class ="io.mycat.route.function.PartitionByMod" > <property name ="count" > 3</property > </function > <function name ="func1" class ="io.mycat.route.function.PartitionByLong" > <property name ="partitionCount" > 8</property > <property name ="partitionLength" > 128</property > </function > <function name ="partition-by-fixed-hash" class ="io.mycat.route.function.PartitionByLong" > <property name ="partitionCount" > 1,1</property > <property name ="partitionLength" > 256,768</property > </function > <function name ="latestMonth" class ="io.mycat.route.function.LatestMonthPartion" > <property name ="splitOneDay" > 24</property > </function > <function name ="partbymonth" class ="io.mycat.route.function.PartitionByMonth" > <property name ="dateFormat" > yyyy-MM-dd</property > <property name ="sBeginDate" > 2015-01-01</property > </function > <function name ="partbyday" class ="io.mycat.route.function.PartitionByDate" > <property name ="dateFormat" > yyyy-MM-dd</property > <property name ="sNaturalDay" > 0</property > <property name ="sBeginDate" > 2020-01-01</property > <property name ="sPartionDay" > 10</property > </function > <function name ="rang-mod" class ="io.mycat.route.function.PartitionByRangeMod" > <property name ="mapFile" > partition-range-mod.txt</property > </function > <function name ="jump-consistent-hash" class ="io.mycat.route.function.PartitionByJumpConsistentHash" > <property name ="totalBuckets" > 3</property > </function > <function name ="sharding-by-hour-function" class ="io.mycat.route.function.LatestMonthPartion" > <property name ="splitOneDay" > 2</property > </function > <function name ="sharding-by-month-function" class ="io.mycat.route.function.PartitionByMonth" > <property name ="dateFormat" > yyyy-MM-dd</property > <property name ="sBeginDate" > 2020-05-01</property > </function > </mycat:rule >
2)修改/conf下migrateTables.properties,指定虚拟库和表
3)修改/bin下dataMigrate.sh
修改该文件编码格式由原有dos修改为unix
#查看文件格式 :set ff #修改文件格式 :set ff=unix
修改mysqldump文件路径
#查看mysqldump文件路径 find / -name mysqldump #修改dataMigrate.sh文件配置 RUN_CMD="$RUN_CMD -mysqlBin=/usr/bin/"
4)执行数据扩容与迁移
5)执行后结果
ps:执行数据扩容&迁移时,务必注意虚拟库的名称必须要全部是小写,不能大小写混合
6)数据迁移后还应考虑后续的数据查询,此时还需将文件进行替换,用于查询路由。
mv newRule.xml rule.xml mv newSchema.xml schema.xml
8.3)Haproxy+keepalived+mycat高可用负载均衡集群 当线上服务器压力过大时,可以考虑基于keepalived进行高可用避免出现mycat单点问题,同时为了防止线上压力集中在某一台实例上,可以通过haproxy进行请求的负载均衡。
8.3.1)mycat准备 142&145两台机器准备mycat-server并启动
8.3.2)haproxy安装&配置 docker pull haproxy:1.9.6 global log 127.0 .0 .1 local2 maxconn 4000 daemon defaults log global log 127.0 .0 .1 local3 mode http option tcplog option dontlognull retries 10 option redispatch maxconn 2000 timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s listen admin_stats bind 0.0 .0 .0 :10080 mode http option httplog maxconn 10 stats refresh 30s stats uri /stats stats realm XingCloud/ Haproxy stats auth admin:admin stats hide-version stats admin if TRUE listen mycat bind 0.0 .0 .0 :3300 mode tcp balance roundrobin server mycat-180 192.168 .200 .180 :8066 check port 8066 maxconn 300 server mycat-181 192.168 .200 .181 :8066 check port 8066 maxconn 300 docker run -d --name haproxy -p 10080 :10080 -v /usr/local/haproxy:/usr/local/etc/haproxy haproxy:1.9.6 http://192.168.200.142:10080/stats
http://192.168.200.142:10080/stats 帐号:admin 密码:admin
8.3.3)keepalived安装&配置 1)安装epel-release源
yum list installed|grep epel-release
2)查找可用安装源
3)keepAlived安装
yum install keepalived -y
4)安装虚拟服务器管理命令
5)编写执行shell脚本
# vi /etc/keepalived/chk.sh # if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then killall keepalived fi
6)配置keepAlived配置文件
cd /etc/keepalived vi keepalvied.conf ! Configuration File for keepalived #简单的头部,这里主要可以做邮件通知报警等的设置,此处就暂不配置了; global_defs { #notificationd LVS_DEVEL } #预先定义一个脚本,方便后面调用,也可以定义多个,方便选择; vrrp_script chk_haproxy { script "/etc/keepalived/check.sh" interval 2 #脚本循环运行间隔 } #VRRP虚拟路由冗余协议配置 vrrp_instance VI_1 { #VI_1 是自定义的名称; state BACKUP #MASTER表示是一台主设备,BACKUP表示为备用设备【我们这里因为设置为开启不抢占,所以都设置为备用】 nopreempt #开启不抢占 interface ens33 #指定VIP需要绑定的物理网卡 virtual_router_id 11 #VRID虚拟路由标识,也叫做分组名称,该组内的设备需要相同 priority 130 #定义这台设备的优先级 1-254;开启了不抢占,所以此处优先级必须高于另一台 advert_int 1 #生存检测时的组播信息发送间隔,组内一致 authentication { #设置验证信息,组内一致 auth_type PASS #有PASS 和 AH 两种,常用 PASS auth_pass 111111 #密码 } virtual_ipaddress { 192.168.200.200 #指定VIP地址,组内一致,可以设置多个IP } track_script { #使用在这个域中使用预先定义的脚本,上面定义的 chk_haproxy } }
7)启动keepAlived
systemctl start keepalived
8)查看keepAlived执行状态
9)此时通过ip a可以看到优先级高的机器已经有了虚拟ip
10)访问haproxy
192.168.200.200:10080/stats 访问成功
11)访问mycat
访问成功,现在已经成功通过keepalived+haproxy跳转到mycat上。
9)Mycat企业级运维 9.1)Mycat-Web性能监控平台 在现在的企业开发中,作为一个合格的开发人员来说,不仅要完成正常的编码任务,同时也要掌握一定的运维能力。当线上系统出现问题时,要能够快速的将隐藏问题找出来并进行解决。
Mycat-web是mycat的可视化运维监控平台。其能够管理和监控mycat的流量、连接数、线程数、JVM、内存。并且基于内部统计还能够分析出慢SQL与高频SQL。为sql优化提供了重要的依据。
9.1.1)Mycat-web安装 1)安装zookeeper
#创建zk文件夹 mkdir -p /usr/local/zookeeper #在zk文件夹下下载zk安装包 wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz #解压安装包 tar -zxvf zookeeper-3.4.9.tar.gz #进入/conf文件夹,修改配置文件名称 cp zoo_sample.cfg zoo.cfg #修改配置文件内容 # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/services/zookeeper/zookeeper-3.4.9/data dataLogDir=/usr/local/services/zookeeper/zookeeper-3.4.9/logs # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 #配置环境变量 export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.9/ export PATH=$JAVA_HOME/bin:$PATH:$MYCAT_HOME/bin:$ZOOKEEPER_HOME/bin #启动zk zkServer.sh start
2)Mycat-web安装
#解压mycat安装包 tar -zxvf Mycat-web-1.0-SNAPSHOT-20170102153329-linux.tar.gz #启动mycat-web,默认端口8082 ./start.sh #查看mycat-web是否启动成功 netstat -ant | grep 8082 #访问mycat-web ip:8082/mycat
9.1.2)mycat-web使用 mycat-web的使用非常简单,其内部已经提供了mycat配置、mycat监控、sql监控与sql上线检查。只需要在其内部配置好自己的mycat服务器信息即可完成使用。
9.2)Mycat调优 在mycat使用过程中,也有可能涉及到对其进行调优。对于mycat调优主要是从JVM、操作系统、mycat本身、缓存、I/O、mysql这几部分分别进行调优
9.2.1)JVM优化 JVM调优主要分为两部分堆内存 和直接内存 。直接内存尽可能的大,合理情况下应在操作系统的50%~67%之间。以16G内存服务器为例:
-server -Xms4G -Mmx4G XX:MaxPermSize=64M -XX:MaxDirectMemorySize=6G
Mycat中JVM参数修改可配置/conf/wrapper.conf
wrapper.java.additional.4 =-XX:MaxDirectMemorySize=2G
9.2.2)操作系统优化 Linux系统对每个进行打开的文件句柄数量是有限的,可以把mysql和mycat服务器的最大文件句柄数量设置为5000~10000,可以通过ulimit命令修改,但只对当前用户有效,且服务器重启后失效。
9.2.3)mycat优化 修改/conf/server.xml
<property name ="processors" > 1</property > <property name ="processorExecutor" > 32</property >
修改/conf/schema.xml
<schema name ="userDB" checkSQLschema ="true" dataNode ="dn142" sqlMaxLimit ="500" > </schema > <dataHost name ="dh142" balance ="3" maxCon ="100" minCon ="10" dbType ="mysql" dbDriver ="jdbc" writeType ="0" switchType ="1" slaveThreshold ="1000" > </dataHost >
9.2.4)缓存优化 在mycat中通过show @@cache可以查看当前mycat缓存的使用情况
mysql -umycat -h192.168.200.142 -P9066 -pmycat show @@cache
如果CUR接近MAX,而PUT比MAX大很多,则表明MAX需要增大。HIT/ACCESS为缓存命中率,该值越高越好。当调整后需要观察缓存命中率是否增加、PUT是否在下降。
可以修改**/conf/cacheservice.properties**修改缓存配置,其使用的是encache,在encache.xml中设置了encache缓存的全局属性
factory.encache =io.mycat.cache.impl.EnchachePooFactory pool.SQLRouteCache =encache,10000,1800 pool.ER_SQL2PARENTID =encache,1000,1800 layedpool.TableID2DataNodeCache =encache,10000,18000 layedpool.TableID2DataNodeCache.TESTDB_ORDERS =50000,18000




















 6.8.1.2)
6.8.1.2)