
Mycat核心概念&源码部署
Mycat核心概念&源码部署
jwangMycat简介
当对数据拆分后会产生诸多的问题,对于这些问题的解决,可以借助于数据库中间件来进行解决,现在时下比较流行的是使用Mycat。
Mycat是一款数据库中间件,对于应用程序来说是完全透明化的,不管底层的数据如何拆分,应用只需要连接Mycat即可完成对数据的操作。同时它还支持MySQL、SQL Server、Oracle、DB2、PostgreSQL等主流数据库。但是Mycat不会进行数据存储,它只是用于数据的路由。
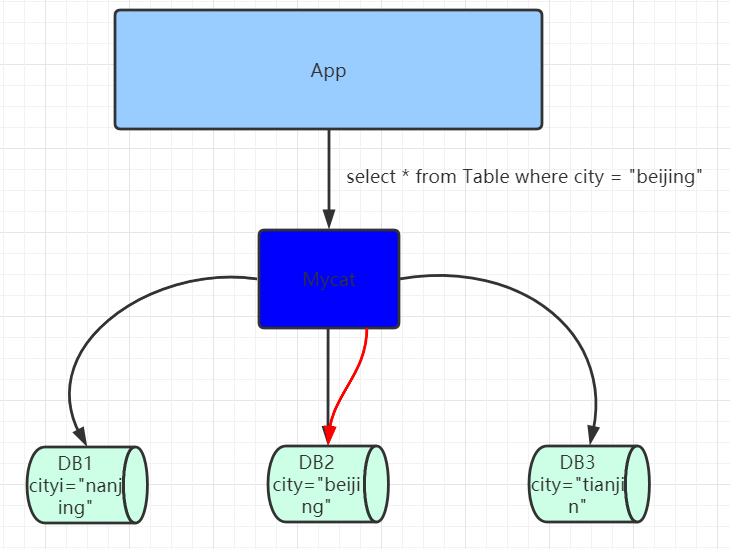
其底层是基于拦截思想实现,其会拦截用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
Mycat特性
- 支持SQL92标准
- 遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
- 基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群。
- 支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
- 基于Nio实现,有效管理线程,高并发问题。
- 支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数。
- 支持单库内部任意join,支持跨库2表join。
- 支持通过全局表,ER关系的分片策略,实现了高效的多表join查询。
- 支持多租户方案。
- 支持分布式事务(弱xa)。
- 支持全局序列号,解决分布式下的主键生成问题。
- 分片规则丰富,插件化开发,易于扩展。
- 强大的web,命令行监控。
- 支持前端作为mysq通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 。
- 支持密码加密
- 支持服务降级
- 支持IP白名单
- 支持SQL黑名单、sql注入攻击拦截
- 支持分表(1.6)
- 集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)。
Mycat源码调试&部署
源码下载:https://codeload.github.com/MyCATApache/Mycat-Server/zip/Mycat-server-1675-release
默认端口:8066
配置启动参数:
-DMYCAT_HOME=D:/workspace/Mycat-Server-Mycat-server-1675-release/src/main |
为什么要设置堆外内存:当使用mycat对非分片查询时,会把所有的数据查询出来,然后把这部分数据放在堆外内存中
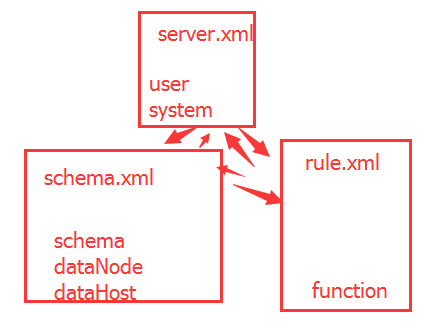
在Mycat有核心三个配置文件,分别为:sever.xml、schema.xml、rule.xml
- server.xml:是Mycat服务器参数调整和用户授权的配置文件。
- schema.xml:是逻辑库定义和表以及分片定义的配置文件
- rule.xml:是分片规则的配置文件,分片规则的具体一些参数信息单独存放为文件,也在这个目录下,配置文件修改需要重启MyCAT。
MyCat核心概念
在学习Mycat首先需要先对其内部一些核心概念有足够的了解。
- 逻辑库:Mycat中的虚拟数据库。对应实际数据库的概念。在没有使用mycat时,应用需要确定当前连接的数据库等信息,那么当使用mycat后,也需要先虚拟一个数据库,用于应用的连接。
- 逻辑表:mycat中的虚拟数据表。对应时间数据库中数据表的概念。
- 非分片表:没有进行数据切分的表。
- 分片表:已经被数据拆分的表,每个分片表中都有原有数据表的一部分数据。多张分片表可以构成一个完整数据表。
- ER表:子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据Join不会跨库操作。表分组(Table Group)是解决跨分片数据join的一种很好的思路,也是数据切分规划的重要一条规则
- 全局表:可以理解为是一张数据冗余表,如状态表,每一个数据分片节点又保存了一份状态表数据。数据冗余是解决跨分片数据join的一种很好的思路,也是数据切分规划的另外一条重要规则。
- 分片节点(dataNode):数据切分后,每一个数据分片表所在的数据库就是分片节点。
- 节点主机(dataHost):数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
- 分片规则(rule):按照某种业务规则把数据分到某个分片的规则就是分片规则。
- 全局序列号(sequence):也可以理解为分布式id。数据切分后,原有的关系数据库中的主键约束在分布式条件下将无法使用,因此需要引入外部机制保证数据唯一性标识,这种保证全局性的数据唯一标识的机制就是全局序列号(sequence),如UUID、雪花算法等。





