Mycat企业级应用实践
Mycat企业级应用实践
jwang环境参数配置
在server.xml 文件中的system标签下配置所有的参数,全部为环境参数,可以根据当前需要进行开启和配置,如:设置mycat连接端口号
<property name="serverPort">8066</property> |

数据非分片
配置初始化信息
应用连接mycat的话,也需要设置用户名、密码、被连接数据库信息,要配置这些信息的话,可以修改server.xml,在其内部添加内容如下:
<!--配置自定义用户信息--> |
配置虚拟数据库&表
当配置了一个虚拟数据库后,还需要修改schema.xml,对虚拟库进行详细配置
|
测试
通过navicat创建本地数据库连接并创建对应数据库,同时创建mycat连接。 在mycat连接中操作表,添加数据,可以发现,本地数据库中同步的也新增了对应的数据。

根据ID取模数据分片
当一个数据表中的数据量非常大时,就需要考虑对表内数据进行分片,拆分的规则有很多种,比较简单的一种就是,通过对id进行取模,完成数据分片。
1)修改schema.xml
table标签新增属性:subTables、rule
|
2)修改rule.xml
在schema.xml中已经指定规则为mod-long。因此需要到该文件中修改对应信息。
<tableRule name="mod-long"> |
3)测试
1)向数据库中插入一千条数据,可以发现,其会根据id取模,放入不同的三张表中。



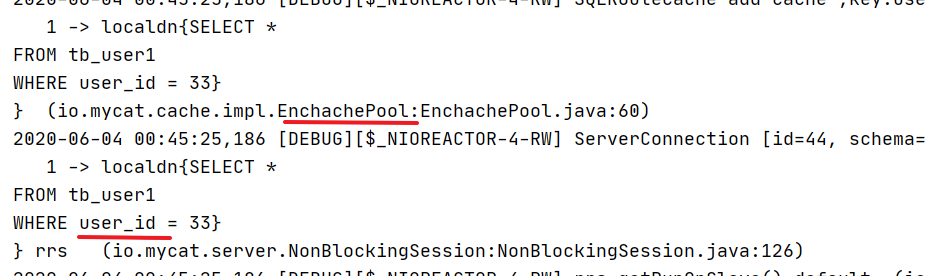
2)当根据id查询时,会通过对id的取模,确定当前要查询的分片。并且首先会先查询mycat中的ehcache缓存,再来查询数据分片
3)当查询所有数据时,会查询所有数据分片。
4)缺陷
通过id取模分片这种方式实际中应用较少。主要因为两点问题:
根据id取模,1)散列不均匀,出现数据倾斜。2)动态扩容时,存在rehash,出现数据丢失。
1)数据散列不均匀,容易出现数据倾斜。每张表中的数据量差距较大。
2)动态扩容后,当需要新增表时,需要对模数修改,有可能就会造成当查询某个分片时,在该分片中找不到对应数据。
3)动态扩容后,要进行rehash操作。
全局序列号
当进行数据切分后,数据会存放在多张表中,如果仍然通过数据库自增id的方式,就会出现ID重复的问题,造成数据错乱。所以当拆分完数据后,需要让每一条数据都有自己的ID,并且在多表中不能出现重复。比较常见的会使用雪花算法来生成分布式id。
在Mycat中也提供了四种方式来进行分布式id生成:基于文件、基于数据库、基于时间戳和基于ZK。
基于本地文件方式生成
优点:本地加载,读取速度较快。
缺点:当MyCAT重新发布后,配置文件中的sequence会恢复到初始值。
生成的id没有含义,如时间。
MyCat如果存在多个,会出现id重复问题。
1)修改sequence_conf.properties
USER.HISIDS= #使用过的历史分段,可不配置 |
2)修改server.xml
<!--设置全局序号生成方式 |
3)测试
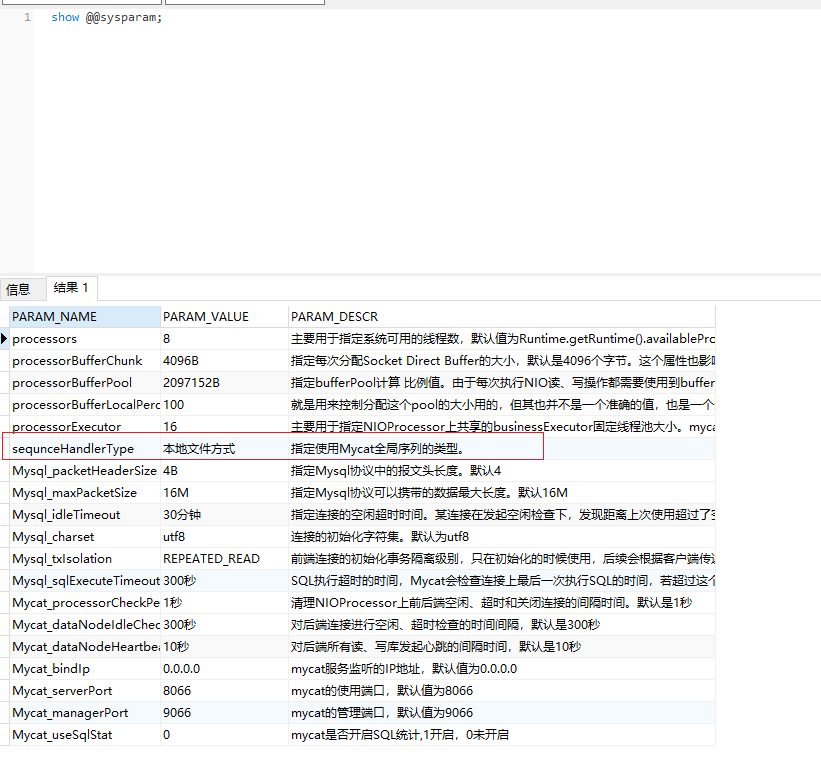
重启mycat,并查询是否修改成功
show @@sysparam |
通过navicat插入数据
insert into tb_user(user_id,user_name) values('next value for MYCATSEQ_USER','wangwu') |
通过程序插入数据
|
基于数据库生成
优点:能够进行id批量生成,在分布式下,可以避免id重复问题。
缺点:ID没有意义,对数据库有压力。
1)在实际数据库执行dbseq.sql中的sql语句,执行完毕后,会创建一张表。

2)修改sequence_db_conf.properties。
TB_USER=localdn |
3)修改server.xml文件,修改全局序列号生成方式为数据库方式
<property name="sequnceHandlerType">1</property> |
4)修改schema.xml。在table中添加自增属性
<table name="tb_user" dataNode="localdn" primaryKey="id" subTables="tb_user$1-3" rule="mod-long" autoIncrement="true"/> |
5)测试
通过navicat新增记录
insert into tb_user(user_id,user_name) values('next value for MYCATSEQ_TB_USER','wangwu') |

基于zookeeper生成
1)修改server.xml,更改生成模式
<property name="sequenceHandlerType">3</property> |
2)修改myid.properties,配置zk连接信息
loadZk=true |
3)修改sequence_distributed_conf.properties
INSTANCEID=ZK #声明使用zk生成 |
4)测试
启动mycatServer后,通过zk客户端查看节点信息。会发现新增了一个mycat节点
./zkCli.sh |

插入数据
insert into tb_user(user_id,user_name) values('next value for MYCATSEQ_TB_USER12','heima') |
next value for MYCATSEQ_ 后的内容可以随意指定。

5)特性:
ID 结构:long 64 位,ID 最大可占 63 位
/* |current time millis(微秒时间戳 38 位,可以使用 17 年)|clusterId(机房或者 ZKid,通过配置文件配置 5位)|instanceId(实例 ID,可以通过 ZK 或者配置文件获取,5 位)|threadId(线程 ID,9 位)|increment(自增,6 位)
/* 一共 63 位,可以承受单机房单机器单线程 1000*(2^6)=640000 的并发。
/* 无悲观锁,无强竞争,吞吐量更高
基于时间戳生成
优点:不存在上面两种方案因为mycat的重启导致id重复的现象
ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加),每毫秒可以并发 12 位二进制的累加。
缺点:数据类型太长,建议采用bigint(最大取值18446744073709551615)
1)修改server.xml。更改生成方式
<property name="sequenceHandlerType">2</property> |
2)修改sequence_time_conf.properties
#sequence depend on TIME |
3)测试
新增数据
insert into tb_user(user_id,user_name) values('next value for MYCATSEQ_TB_USER12','heima') |
next value for MYCATSEQ_ 后的内容可以随意指定。

Mycat分库&读写分离
之前已经基于id取模完成了分表操作,但是一个数据库的容量毕竟是有限制的,如果数据量非常大,分表已经满足不了的话,就会进行分库操作。
当前分库架构如下:
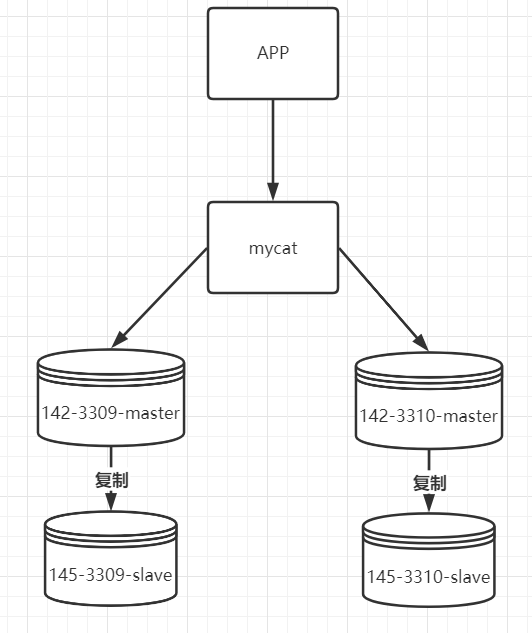
现在存在两个主库,并且各自都有从节点。 当插入数据时,根据id取模放入不同的库中。同时主从间在进行写时复制的同时,还要完成主从读写分离的配置。
1)修改schema.xml。配置多datenode与datahost。同时配置主从读写分离。
|
2)修改rule.xml。配置取模时的模数
<function name="mod-long" class="io.mycat.route.function.PartitionByMod"> |
3)进行批量数据添加,可以发现数据落在了不同的库中。
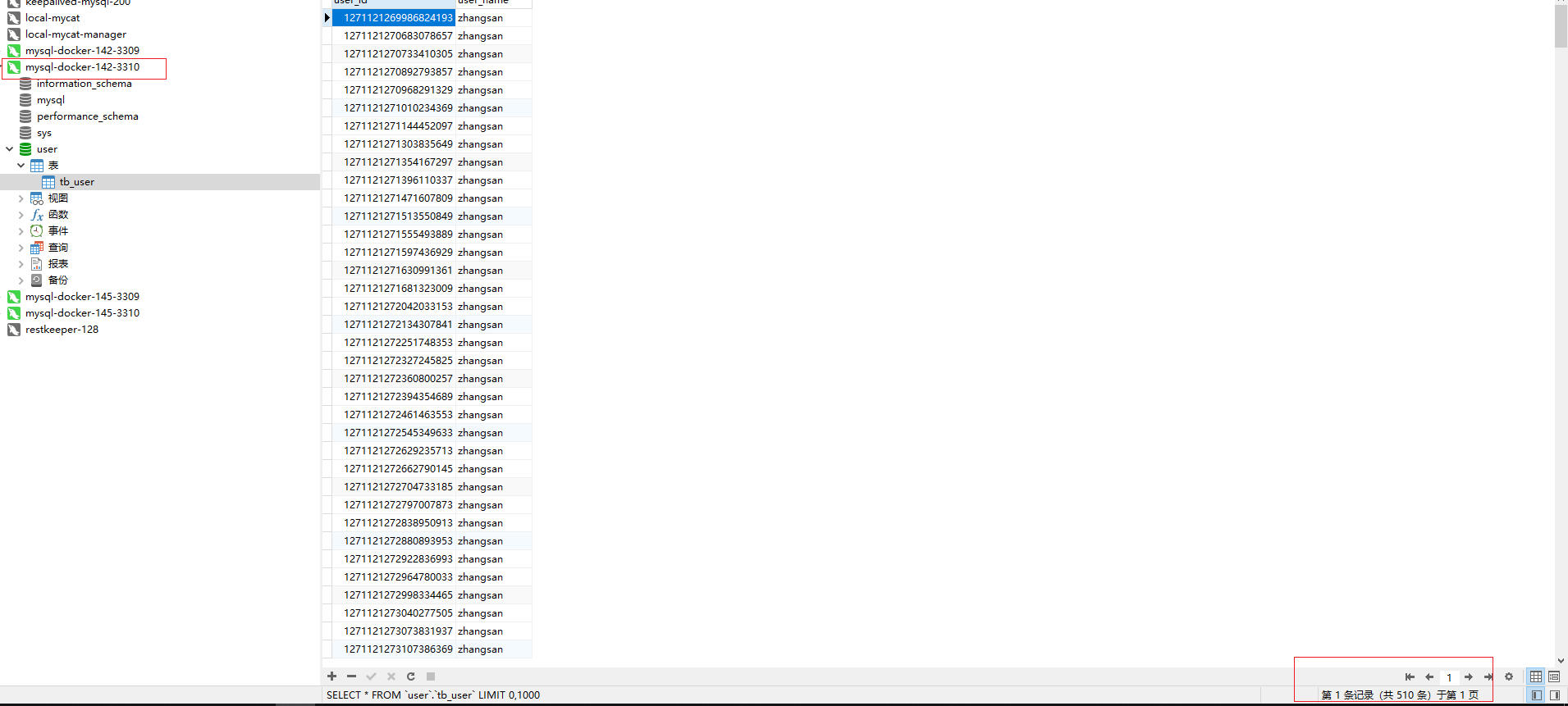
4)读写分离验证
设置log4j2.xml的日志级别为DEBUG
|
基于mysql服务进行数据查看,观察控制台信息,可以看到对于read请求的数据源,分别使用的是配置文件的配置


MyCat分片规则
枚举分片
实现
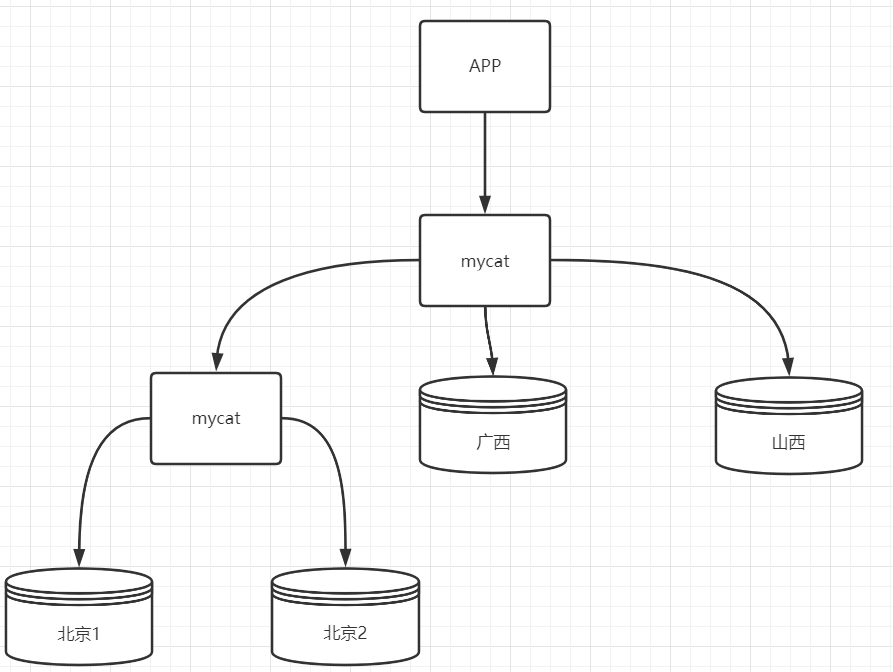
适用于在特定业务场景下,将不同的数据存放于不同的数据库中,如按省份、按人员信息等。
1)修改schema.xml,修改table标签中name属性为当前操作的表名,rule属性为sharding-by-intfile
<table name="tb_user_sharding_by_intfile" dataNode="dn142,dn145" primaryKey="user_id" rule="sharding-by-intfile"/> |
2)修改rule.xml,配置tableRule为sharding-by-intfile中columns属性为当前指定分片字段
<tableRule name="sharding-by-intfile"> |
3)修改rule.xml中hash-int
<function name="hash-int" |
4)修改partition-hash-int.txt。指定分片字段不同值存在于不同的数据库节点
male=0 #代表第一个datanode |
5)执行测试
修改mapper
|
执行测试,此时可以发现,当sex为male时,数据会进入142节点,当sex为female时,数据会进入145节点。

 6.8.1.2)
6.8.1.2)
问题
该方案适用于特定业务场景进行数据分片,但该方式容易出现数据倾斜,如不同省份的订单量一定会不同。订单量大的省份还会进行数据分库,数据库架构就会继续发生对应改变。
固定hash分片
固定hash分片的工作原理类似与redis cluster槽的概念,在固定hash中会有一个范围是0-1024,内部会进行二进制运算操作,如取 id 的二进制低 10 位 与 1111111111 进行 & 运算。从而当出现连接数据插入,其有可能会进入到同一个分片中,减少了分布式事务操作,提升插入效率同时尽量减少了数据倾斜问题,但不能避免不出现数据倾斜。

按照上面这张图就存在两个分区,partition1和partition2。partition1的范围是0-255,partition2的范围是256-1024。
当向分区中存数据时,先将id值转换为二进制,接着&1111111111,再对结果值转换为十进制,从而确定当前数据应该存入哪个分区中。
1023的二进制&1111111111运算后为1023,故落入第二个分区
1024的二进制&1111111111运算后为0,故落入第一个分区
266 的二进制&1111111111运算后为266,故落入第二个分区内
实现
1)修改schema.xml,配置自定义固定hash分配规则
<table name="tb_user_fixed_hash" dataNode="dn142,dn145" primaryKey="user_id" rule="partition-by-fixed-hash"/> |
2)修改rule.xml,配置自定义固定hash分片规则
<tableRule name="partition-by-fixed-hash"> |
3)测试,添加数据,可以发现数据会根据计算,落入相应的数据库节点。
固定范围分片
该规则有点像枚举与固定hash的综合体,设置某一个字段,然后规定该字段值的不同范围值会进入到哪一个dataNode。适用于明确知道分片字段的某个范围属于某个分片
优点:适用于想明确知道某个分片字段的某个范围具体在哪一个节点;
缺点:如果短时间内有大量的批量插入操作,那么某个分片节点可能一下子会承受比较大的数据库压力,而别的分片节点此时可能处于闲置状态,无法利用其它节点进行分担压力(热点数据问题);
1)修改schema.xml。
<table name="tb_user_range" dataNode="dn142,dn145" primaryKey="user_id" rule="auto-sharding-long"/> |
2)修改rule.xml
<tableRule name="auto-sharding-long"> |
3)修改autopartition-long.txt,定义自定义范围
#用于定义dataNode对应的数据范围,如果配置多了会报错。 |
4)测试,添加用户信息,年龄分别为9和33,可以看到,数据落入到对应的数据节点


取模范围分片
这种方式结合了范围分片和取模分片,主要是为后续的数据迁移做准备。
优点:可以自主决定取模后数据的节点分布。
缺点:dataNode 划分节点是事先建好的,需要扩展时比较麻烦。
1)修改schema.xml,配置分片规则
<table name="tb_user_mod_range" dataNode="dn142,dn145" primaryKey="user_id" rule="sharding-by-partition"/> |
2)修改rule.xml,添加分片规则
<tableRule name="sharding-by-partition"> |
3)添加partition-pattern.txt,文件内部配置节点中数据范围
#0-128表示id%256后的数据范围。 |
4)测试
可以发现数据根据id取模并进入到了不同的分片节点中。
字符串hash求模范围分片
在业务场景下,有时可能会根据某个分片字段的前几个值来进行取模。如地址信息只取省份、姓名只取前一个字的姓等。此时则可以使用该种方式。
其工作方式与取模范围分片类型,该分片方式支持数值、符号、字母取模。
1)修改schema.xml。
<table name="tb_user_string_hash" dataNode="dn142,dn145" primaryKey="user_id" rule="sharding-by-string-hash"/> |
2)修改rule.xml,定义拆分规则
<tableRule name="sharding-by-string-hash"> |
3)新建partition-pattern-string-hash.txt。指定数据分片节点
0-128=0 |
4)运行后可以发现 ,不同的姓名取模后,会进入不同的分片节点。
一致性hash分片
通过一致性hash分片可以最大限度的让数据均匀分布,但是均匀分布也会带来问题,就是分布式事务。
原理
一致性hash算法引入了hash环的概念。环的大小是0~2^32-1。首先通过crc16算法计算出数据节点在hash环中的位置。
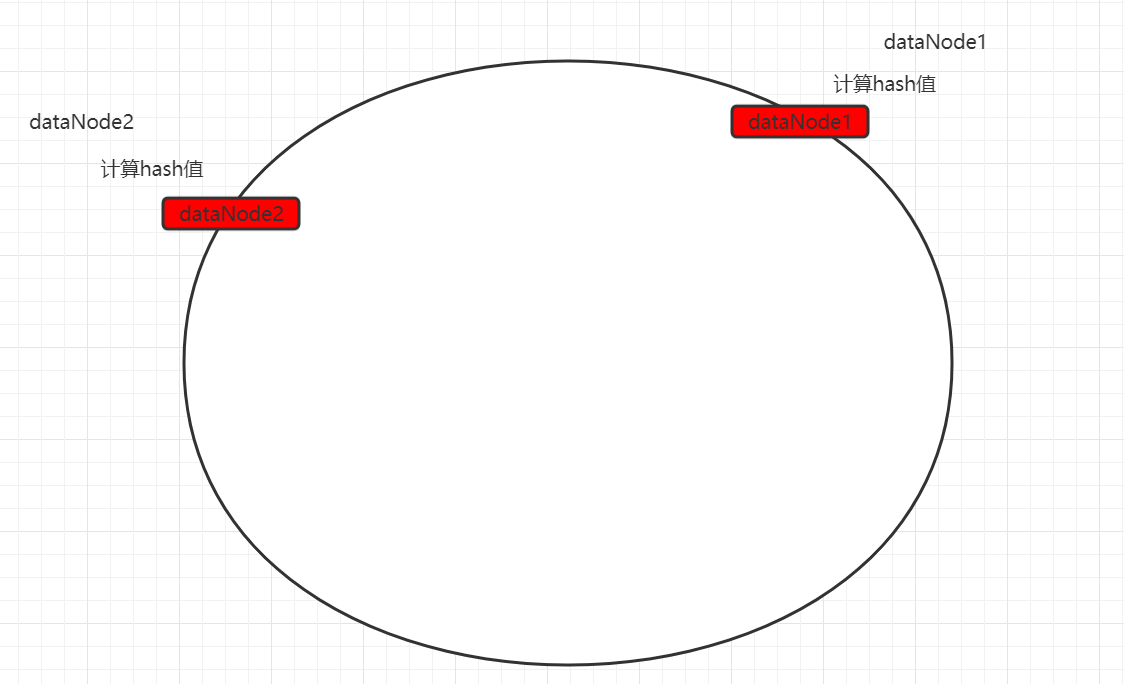
当存储数据时,也会采用同样的算法,计算出数据key的hash值,映射到hash环上。
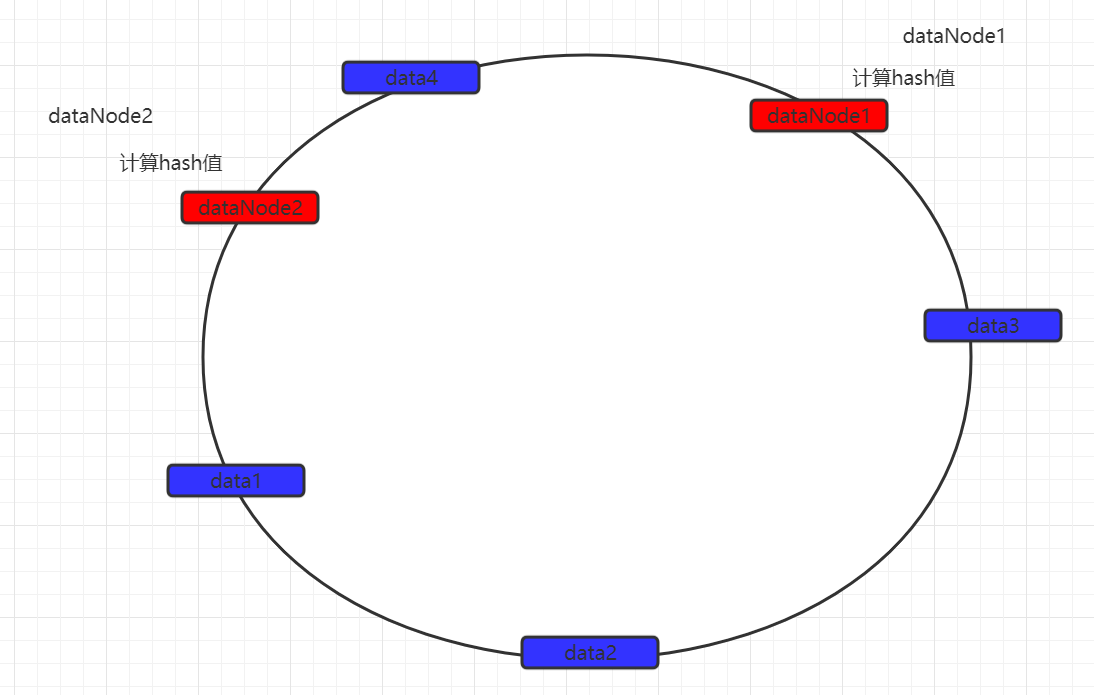
然后从数据映射的位置开始,以顺时针的方式找出距离最近的数据节点,接着将数据存入到该节点中。
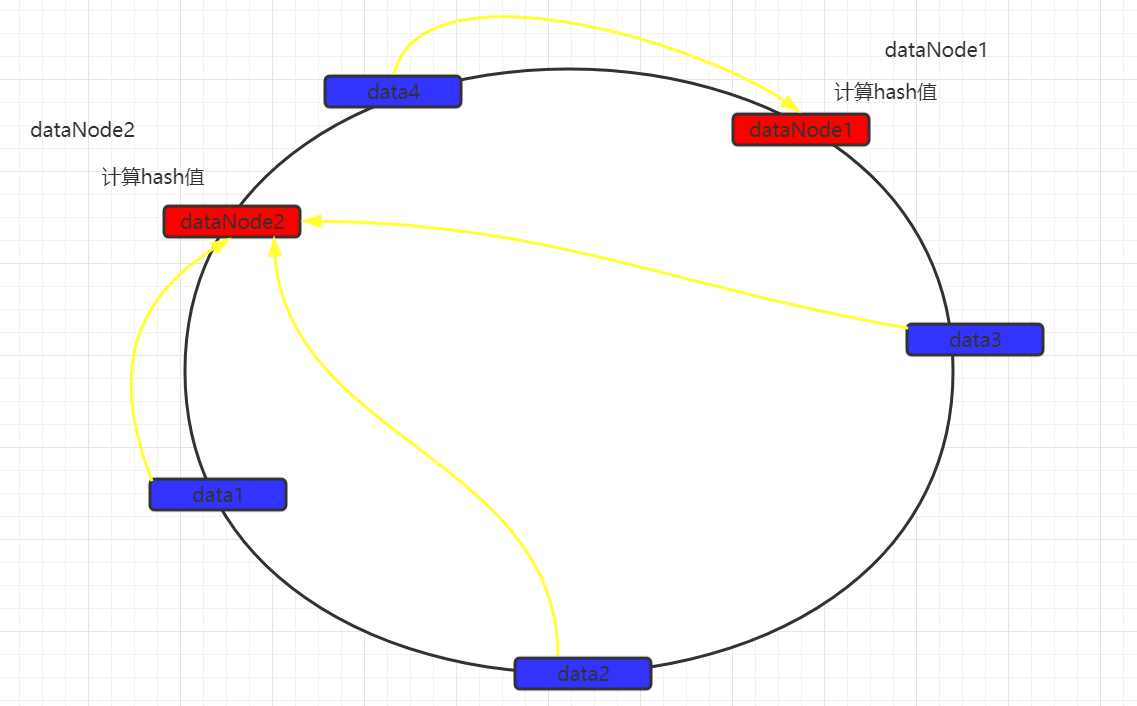
此时可以发现,数据并没有达到预期的数据均匀,可以发现如果两个数据节点在环上的距离,决定有大量数据存入了dataNode2,而仅有少量数据存入dataNode1。
为了解决数据不均匀的问题,在mycat中可以设置虚拟数据映射节点。同时这些虚拟节点会映射到实际数据节点。
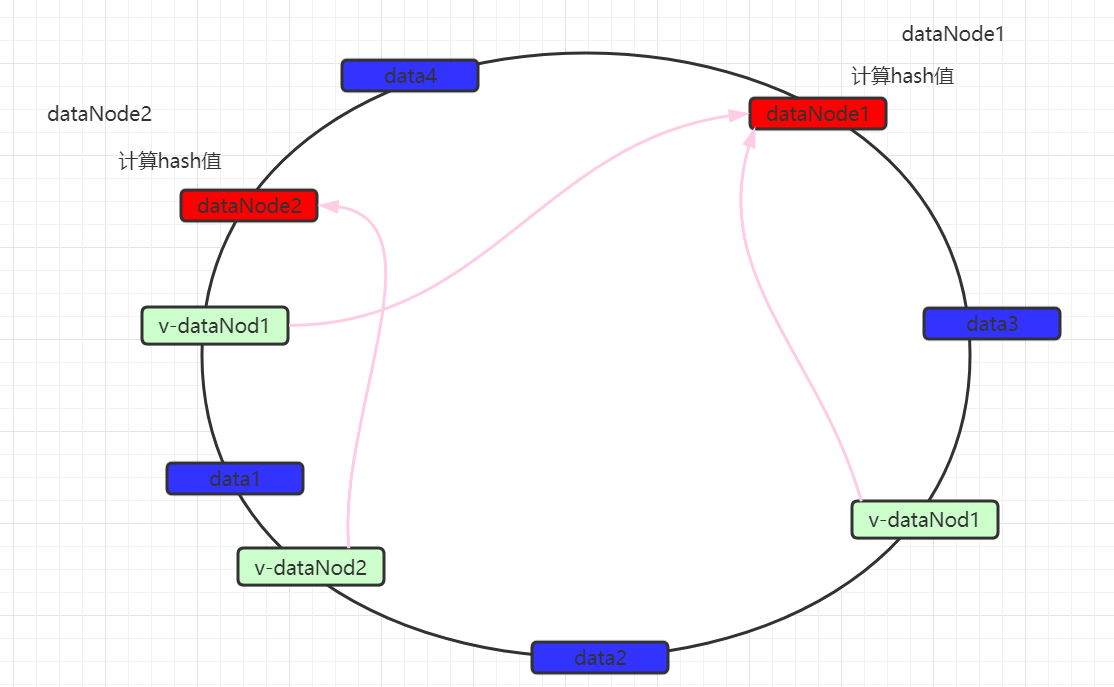
数据仍然以顺时针方式寻找数据节点,当找到最近的数据节点无论是实际还是虚拟,都会进行存储,如果是虚拟数据节点的话,最终会将数据保存到实际数据节点中。 从而尽量的使数据均匀分布。
实现
1)修改schema.xml
<table name="tb_user_murmur" dataNode="dn142,dn145" primaryKey="user_id" rule="sharding-by-murmur"/> |
2)修改rule.xml
<tableRule name="sharding-by-murmur"> |
3)测试
循环插入一千条数据,可以数据会尽量均匀的分布在142和145两个节点中。
时间分片
按天分片
当数据量非常大时,有时会考虑,按天去分库分表。这种场景是非常常见的。同时也有利于后期的数据查询。
1)修改schema.xml
<table name="tb_user_day" dataNode="dn142,dn145" primaryKey="user_id" rule="sharding-by-date"/> |
2)修改rule.xml,每十天一个分片,从起始时间开始计算,分片不够,则报错。
<tableRule name="sharding-by-date"> |
3)测试
|
当时间为1月1-10号之间,会进入142节点。当时间为11-20号之间,会进入145节点,当超出则报错。
按月分片
按月进行数据分片,每月一个分片
1)修改schema.xml
<table name="tb_user_month" dataNode="dn142,dn145" primaryKey="user_id" rule="sharding-by-month"/> |
2)修改rule.xml
<tableRule name="sharding-by-month"> |
3)测试
可以发现当为五月会进入到节点1中,当为六月会进入到节点2中。当为七月则报错,因为需要每月一个分片,当前测试只有两个分片。
跨库join
全局表
简介
系统中基本都会存在数据字典信息,如数据分类信息、项目的配置信息等。这些字典数据最大的特点就是数据量不大并且很少会被改变。同时绝大多数的业务场景都会涉及到字典表的操作。 因此为了避免频繁的跨库join操作,结合冗余数据思想,可以考虑把这些字典信息在每一个分库中都存在一份。
mycat在进行join操作时,当业务表与全局表进行聚合会优先选择相同分片的全局表,从而避免跨库join操作。在进行数据插入时,会把数据同时插入到所有分片的全局表中。
实现
1)修改schema.xml
<table name="tb_global" dataNode="dn142,dn145" primaryKey="global_id" type="global"/> |
2)测试,可以发现会同时向两张表中插入数据

ER表
介绍
ER表也是一种为了避免跨库join的手段,在业务开发时,经常会使用到主从表关系的查询,如商品表与商品详情表。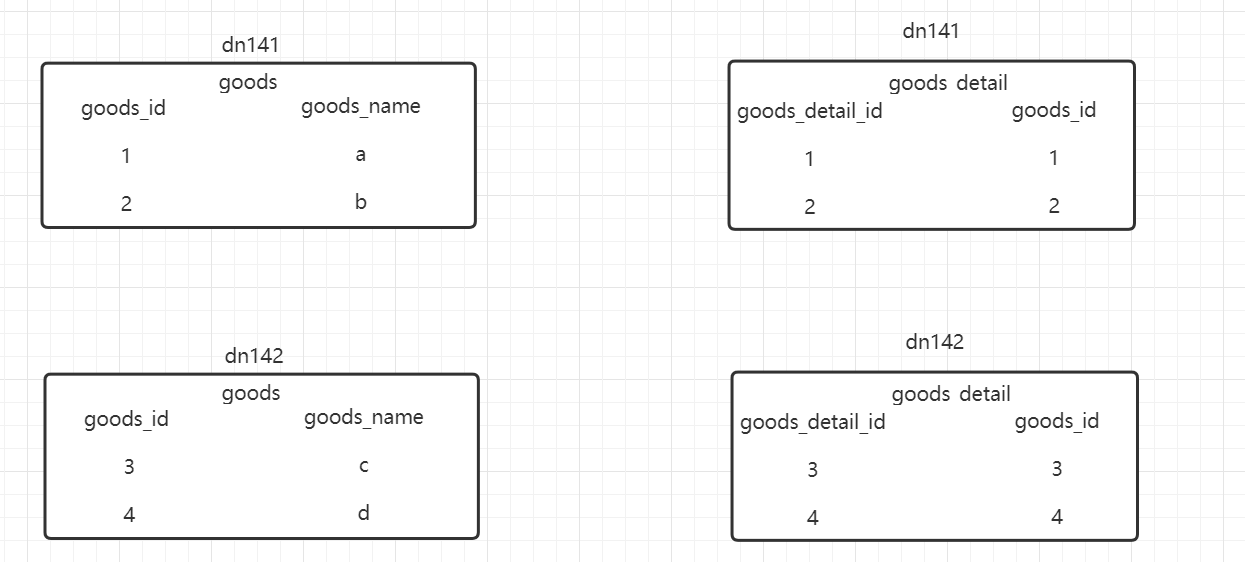
根据上图就是一个简单的表关系,但是现在有可能出现一个问题:goods_detail中goods_id为1,2这两条数据有可能存在于142中。这样就造成了跨库join的问题的。并且在不使用ER表的情况下,还有可能出现数据丢失的问题。
ER表的出现就是为了让有关系的表数据存储于同一个分片中,从而避免跨库join的出现。
不使用ER表问题演示
1)修改schema.xml,配置商品与商品详情表信息
<table name="tb_goods" dataNode="dn142,dn145" primaryKey="goods_id" rule="sharding-by-murmur-goods"/> |
2)修改rule.xml
<tableRule name="sharding-by-murmur-goods"> |
3)插入数据,不要使用自动生成id。
|
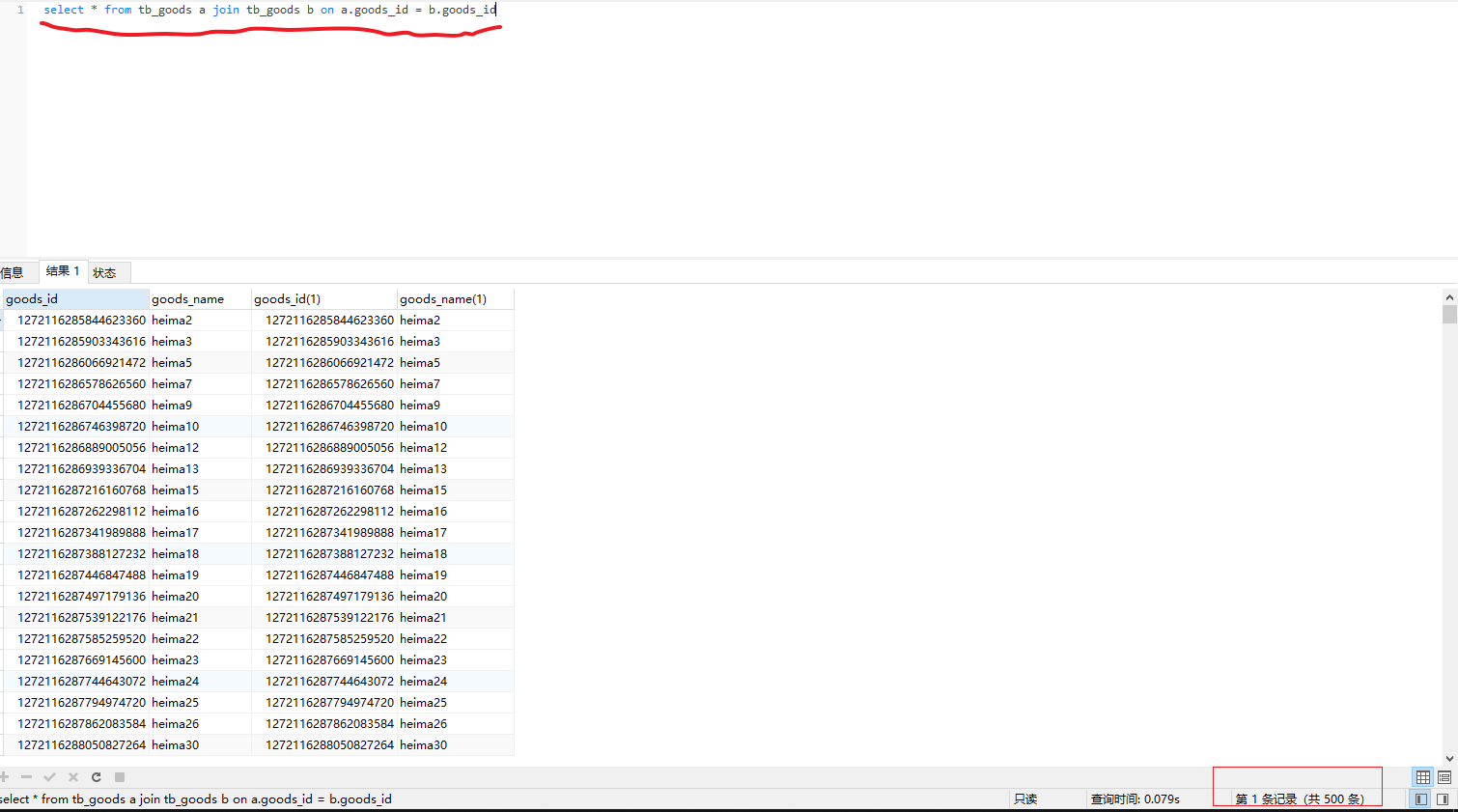
4)连接mycat查询数据,可以发现出现数据丢失。
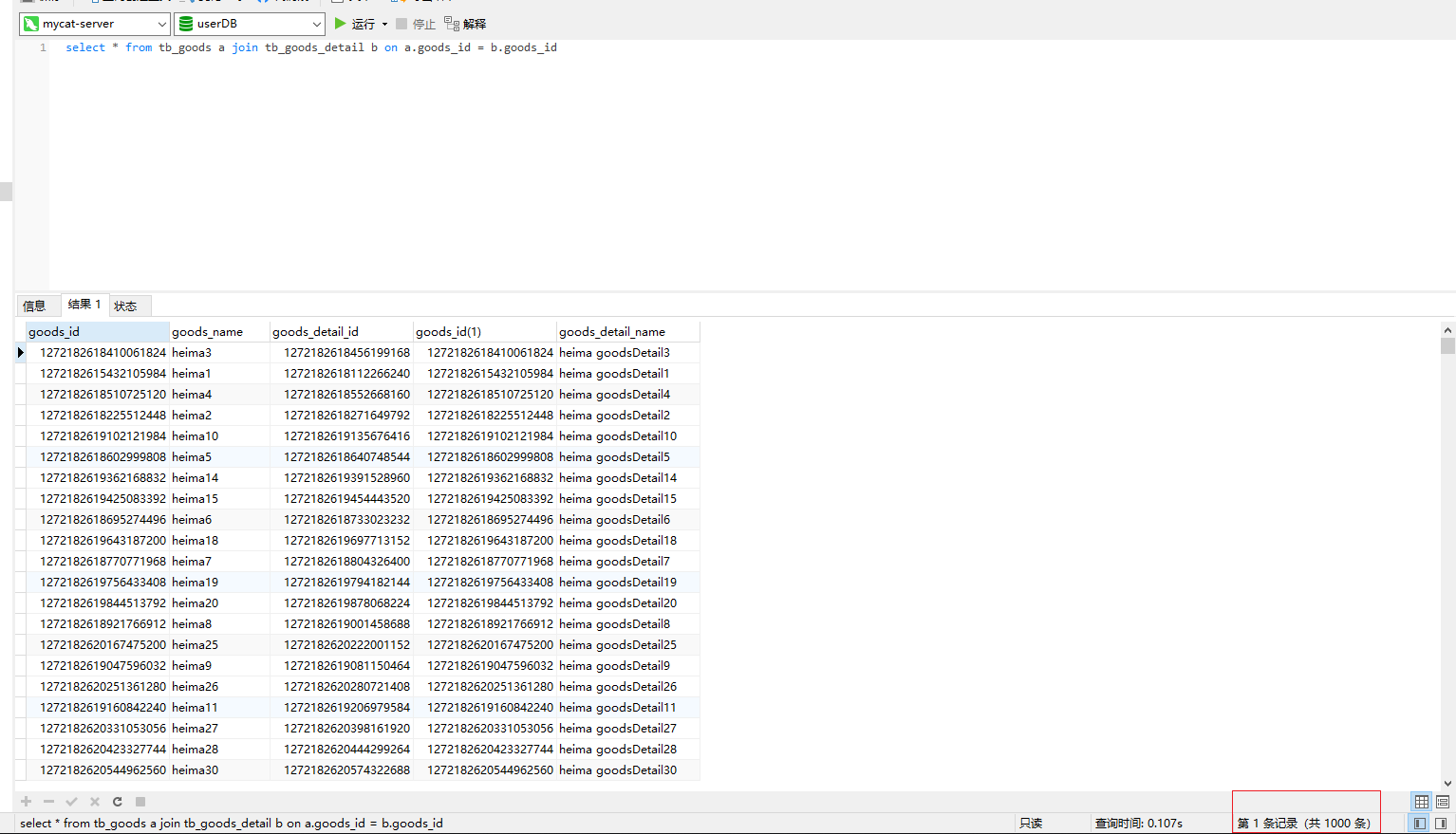
select * from tb_goods a join tb_goods_detail b on a.goods_id = b.goods_id |
ER实现
1)修改schema.xml。配置er表
<table name="tb_goods" dataNode="dn142,dn145" primaryKey="goods_id" rule="sharding-by-murmur-goods"> |
2)测试
删除原有数据,并重新插入数据,此时再次join查询,可以发现全部的一千条数据都已经获取到了。同时有关联关系的数据,也都存在于同一个数据分片中。