
Advanced RAG-索引优化(Pre-Retrieval)

Advanced RAG-索引优化(Pre-Retrieval)
jwang摘要索引
在处理大量文档时,如何快速准确地找到所需信息是一个常见挑战。摘要索引可以用来处理半结构化数据,比如许多文档包含多种内容类型,包括文本和表格。这种半结构化数据对于传统 RAG 来说可能具有挑战性,文本拆分可能会分解表,从而损坏检索中的数据;嵌入表可能会给语义相似性搜索带来挑战。
- 解决方案
1. 让LLM为每个块生成summary,并作为embedding存到summary database中 |
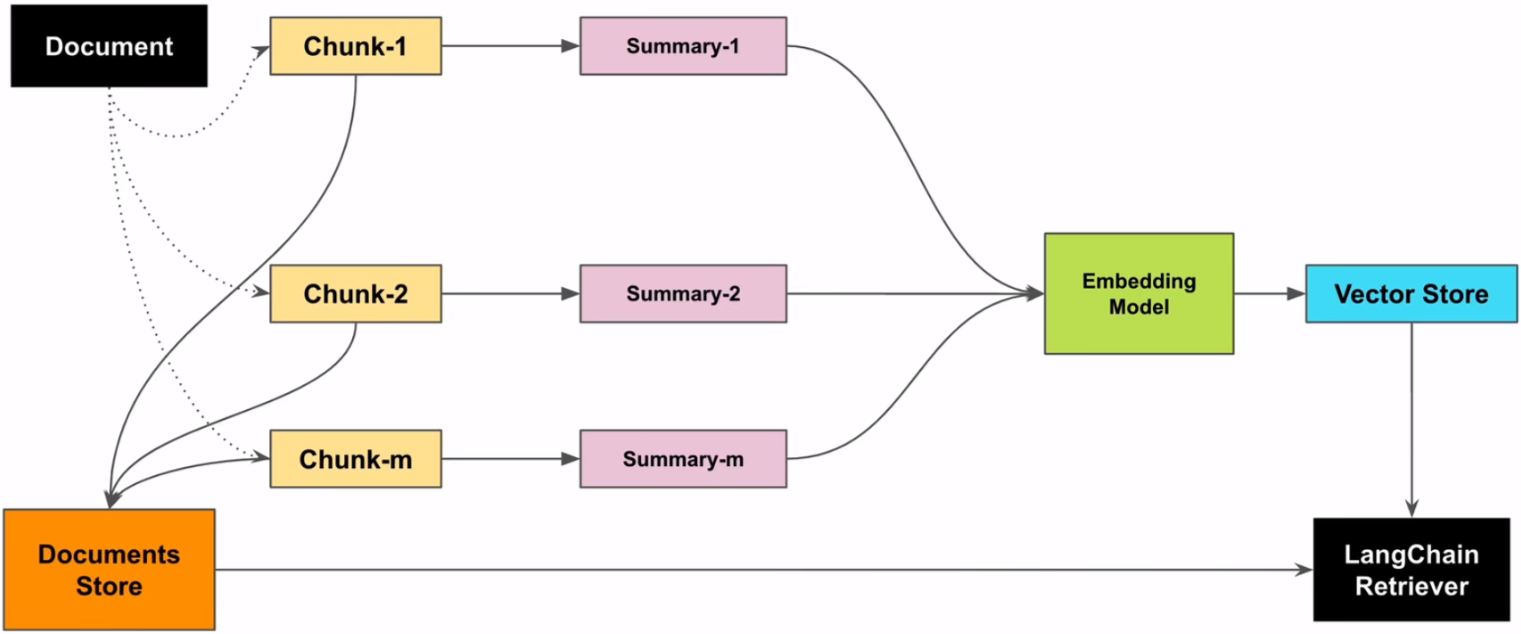
父子索引
我们在利用大模型进行文档检索的时候,常常会有相互矛盾的需求,比如:
- 你可能希望得到较小的文档块,以便它们Embedding以后能够最准确地反映出文档的含义,如果文档块太大,Embedding就失去了意义。
- 你可能希望得到较大的文档块以保留较多的内容,然后将它们发送给LLM以便得到全面且正确的答案。
解决方案
文档被分割成一个层级化的块结构,随后用最小的叶子块进行索引 |
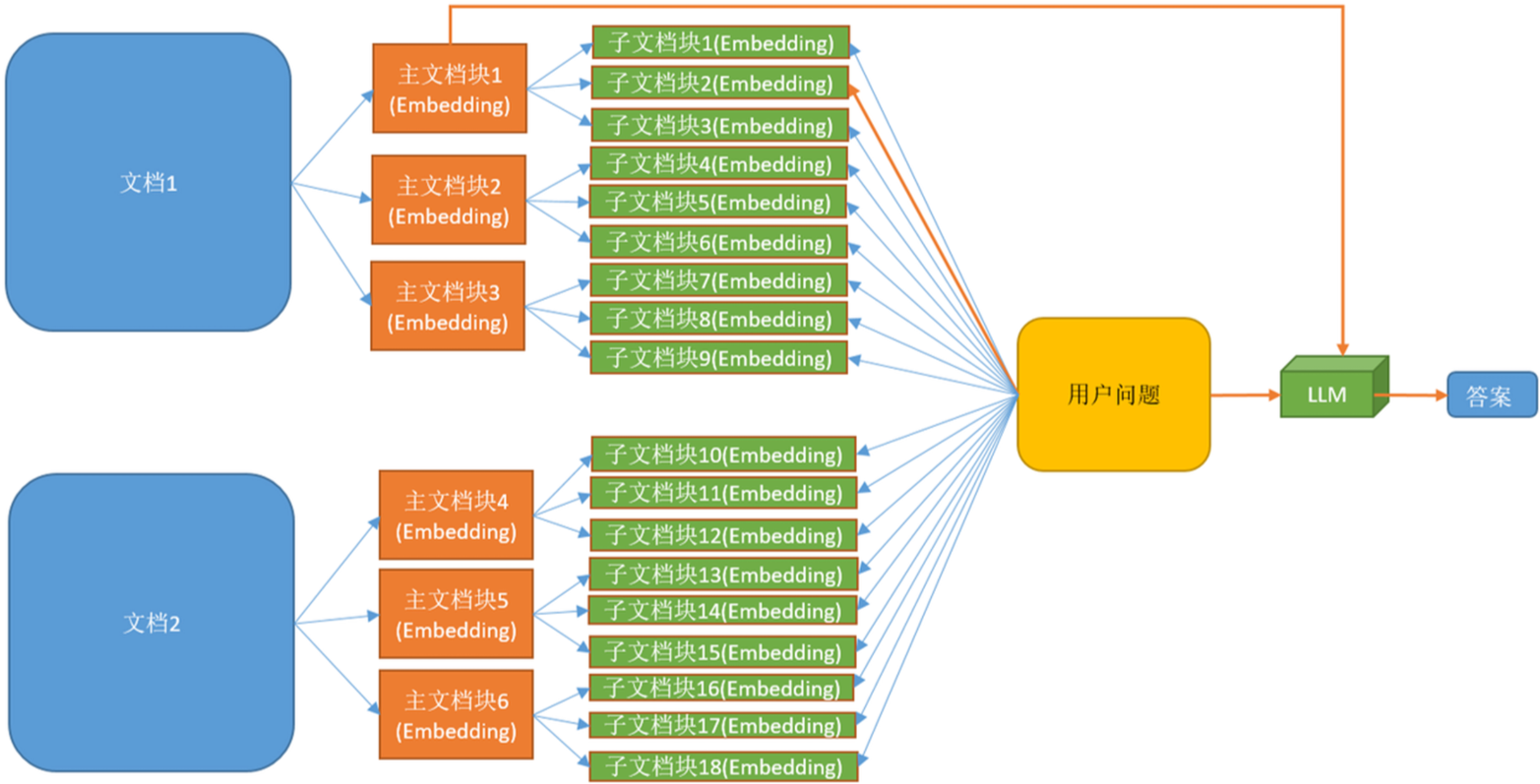
假设性问题索引
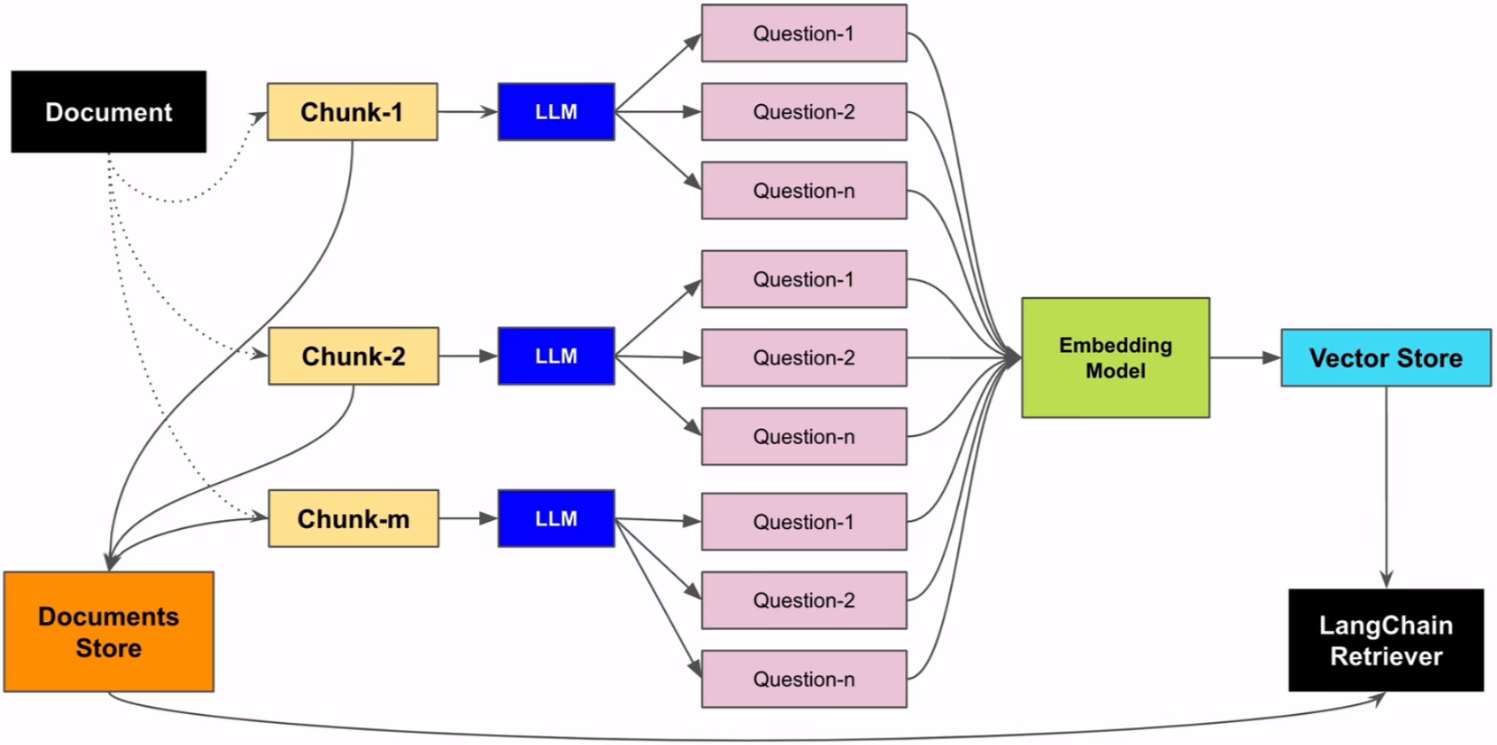
假设性问题是一种提问方式,它基于一个或多个假设的情况或前提来提出问题。在对知识库中文档内容进行切片时,是可以以该切片为假设条件,利用LLM预先设置几个候选的相关性问题的,也就是说,这几个候选的相关性问题是和切片的内容强相关的。
1.让LLM为每个块生成3个假设性问题,并将这些问题以向量形式嵌 |
元数据索引
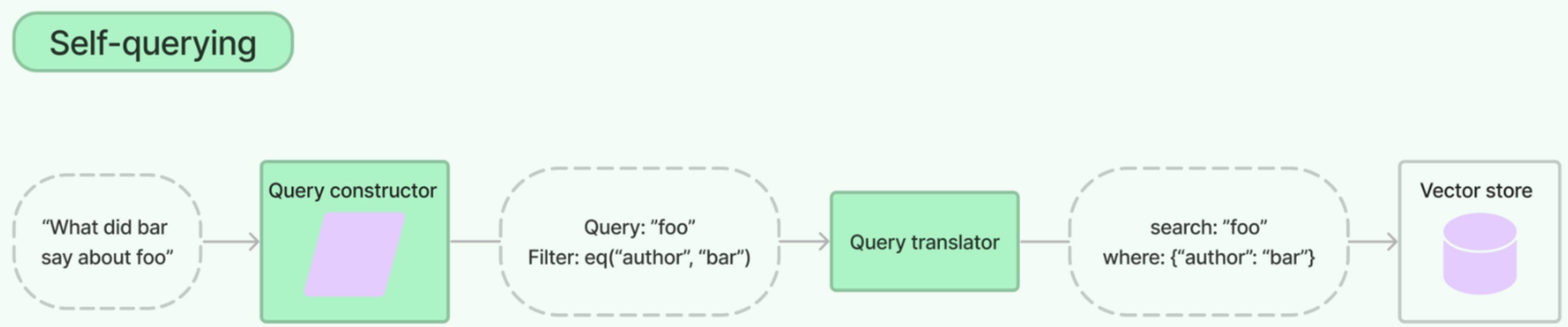
在企业复杂的知识密集型应用中,可能会面临几百个不同来源与类型的知识文档。如果只是简单地依赖传统的文本分割与 top-k 检索,就会产生精度不足、知识相互干扰等问题,从而导致效果不佳。想象一下,你想在一个医学文献数据库中查找关于“糖尿病足”的资料,但数据库中也充斥着大量关于其他糖尿病并发症的信息。
一个重要的优化方法是在大文档集下“分层”过滤与检索。比如元数据索引
元数据是对文档的一种属性描述,假设我们使用一个存储了大量科技博客文章的向量数据库。每篇文章都关联了以下标签: |
- 基本思路(LangChain 中使用SelfQueryRetriever自查询检索器实现)
1.定义元数据标签,如果文档本身没有,可以利用大模型推理出输入问题的元数据 |
各索引适用场景
| 索引优化 | 适用场景 | 案例 |
| 摘要索引 | 适用于需要快速检索和生成简洁上下文的场景。 | 在新闻资讯平台中,系统需要快速从海量新闻中提取关键信息,通过摘要索引可以迅速生成简洁的上下文,帮助用户快速了解新闻的核心内容。 |
| 父子索引 | 适用于需要确保语义完整性和层次化检索的场景。 | 在法律检索系统中,用户查询法律条款时,父子索引通过分层检索精准查找相关内容,并召回对应大文档块确保上下文的完整性,避免因分块过细导致语义丢失。 |
| 假设性问题索引 | 适用于需要处理复杂查询和多样化表达的场景。 | 在药品咨询系统中,用户查询症状时可能会问:“感冒了吃什么药?”。假设性问题索引通过为每种药品生成一系列假设性问题,帮助用户更准确地检索到相关信息。 |
| 元数据索引 | 适用于需要快速筛选和分类的场景。 | 在电商推荐系统中,系统通过元数据索引快速筛选出符合用户偏好的商品信息,提高推荐效率和准确性。 |




