LLM核心-模型训练

LLM核心-模型训练
jwang机器学习
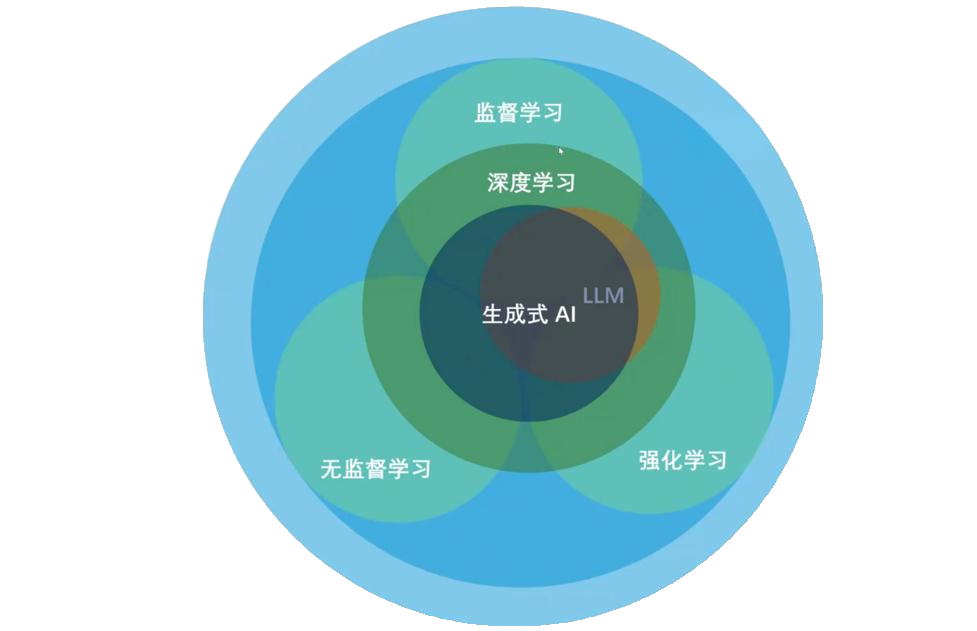
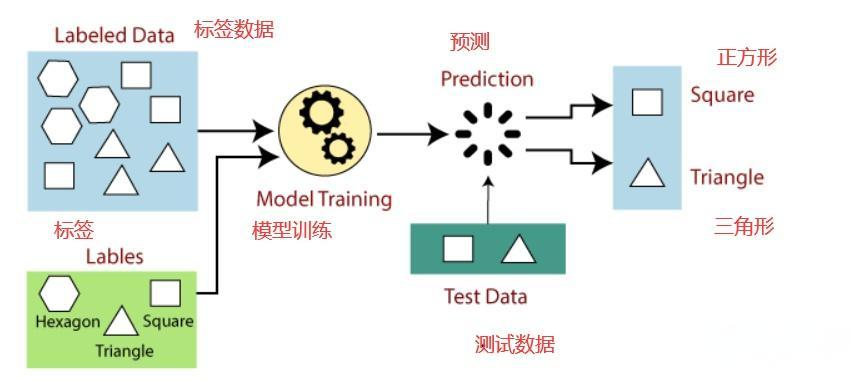
监督学习
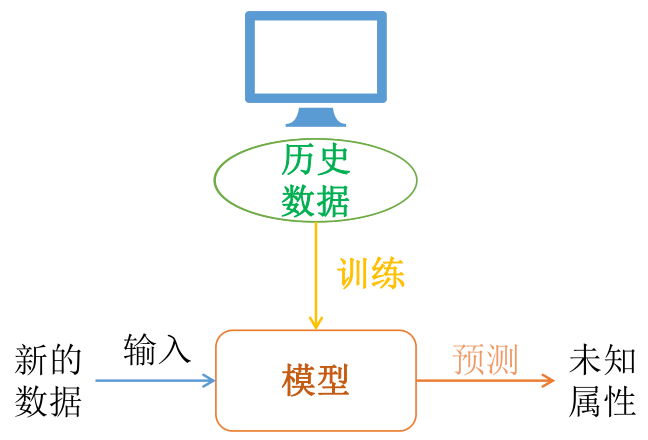
- 人们给机器一大堆标记好的数据
一大堆数据(比如图片),用标签标记出哪些是三角形、哪些是正方形、哪些是六边形 |
无监督学习
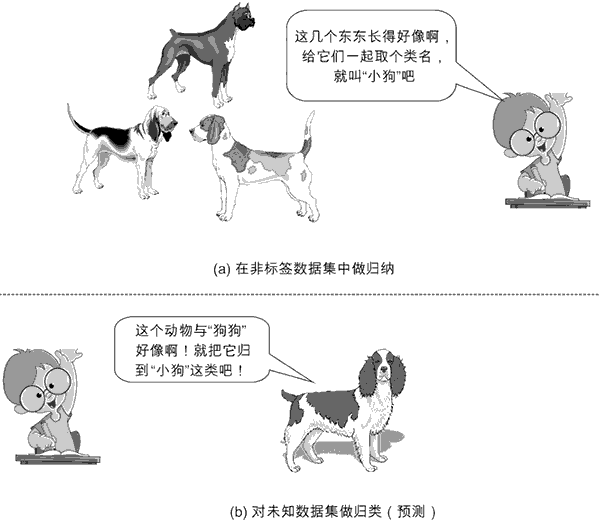
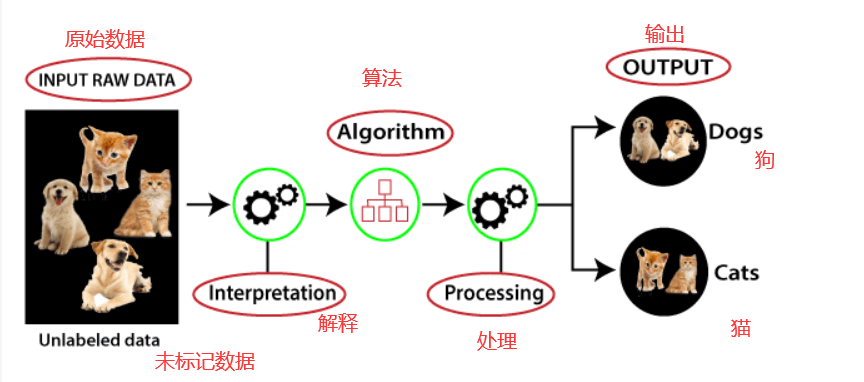
- 无监督学习(unsupervised learning)指的是人们给机器一大堆没有分类标记的数据,让机器自行对数据分类、检测异常等
强化学习
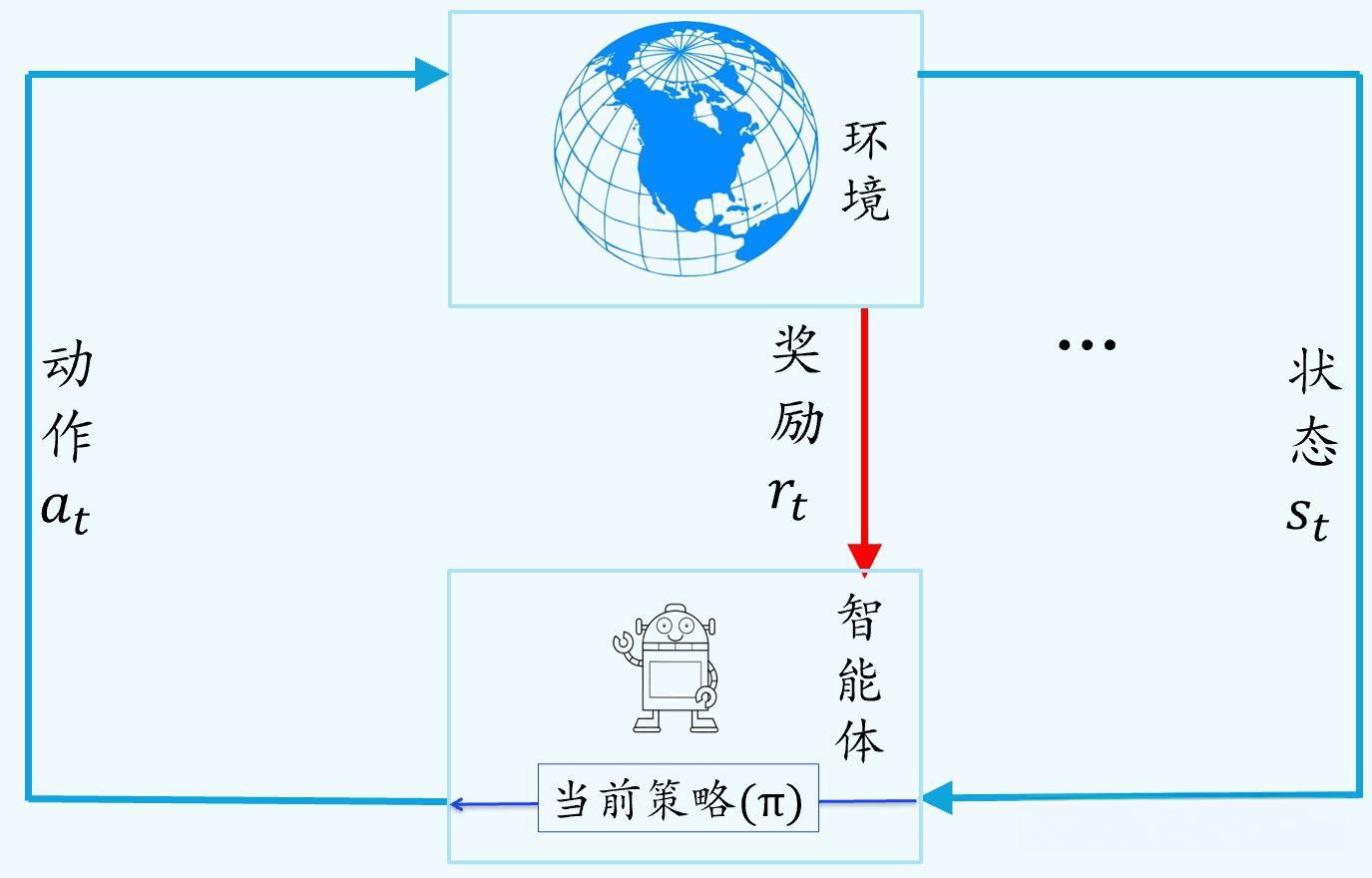
- 强化学习主要用来解决连续决策的问题,强化学习的目标一般是变化的、不明确的,甚至可能不存在绝对正确的标签
- 强化学习可以理解为一种让智能体(比如一个机器人或者一个程序)通过不断尝试和与环境互动来学习如何做出最优决策的方法。根据得到的反馈来调整自己的行为策略, 逐渐学会哪些行动能带来更多奖励,哪些行动会带来负激励或者惩罚,从而找到最优的行动方式
Pre-training预训练阶段
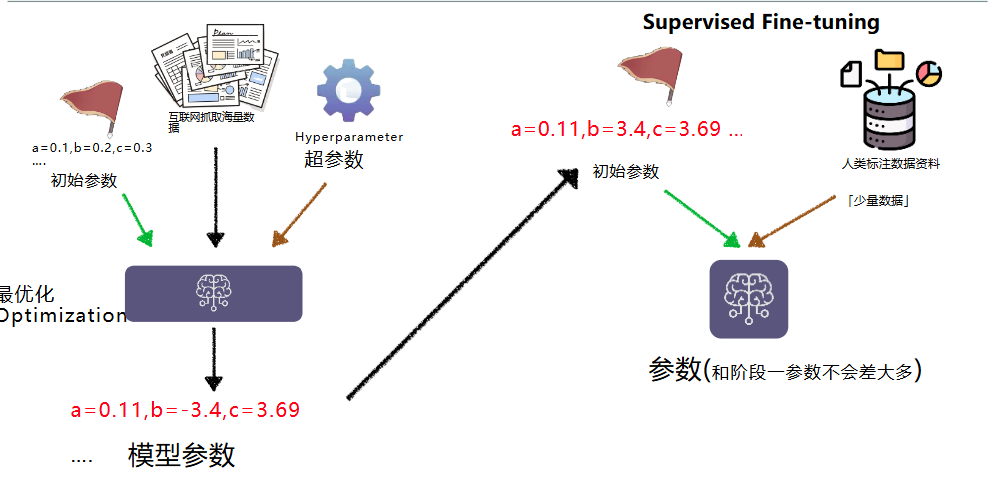
- 通过机器学习的过程不断找参数就是模型的训练(training)
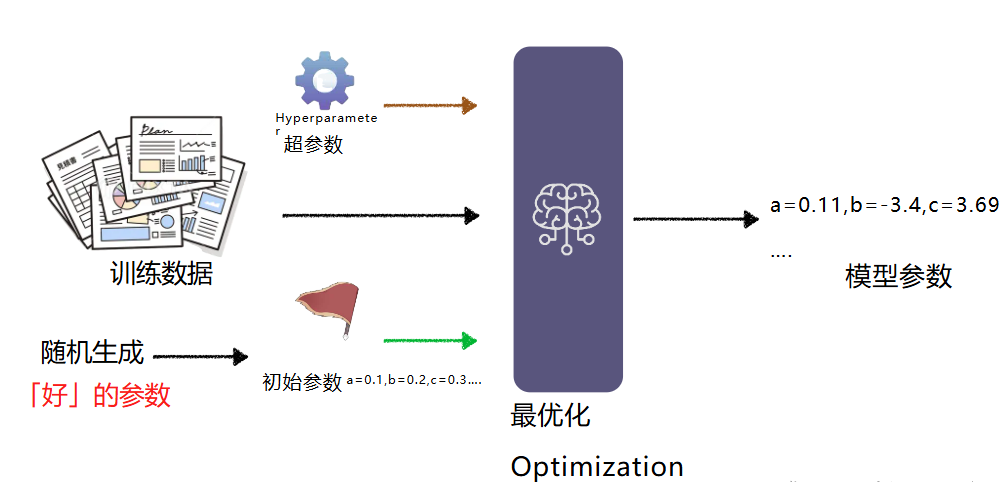
- 训练可能不会一次成功,需要反复调整超参数,上算力再次进行训练(经费在燃烧)
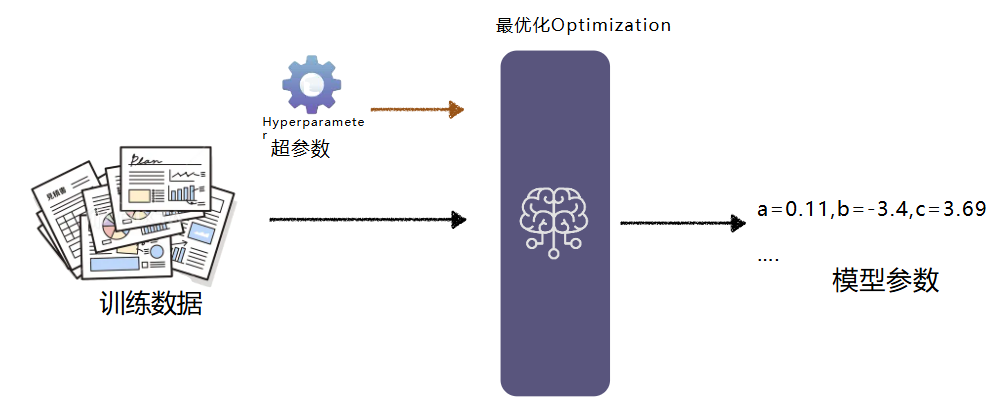
超参数很难一次设置就成功,需要不断的调整后跑模型

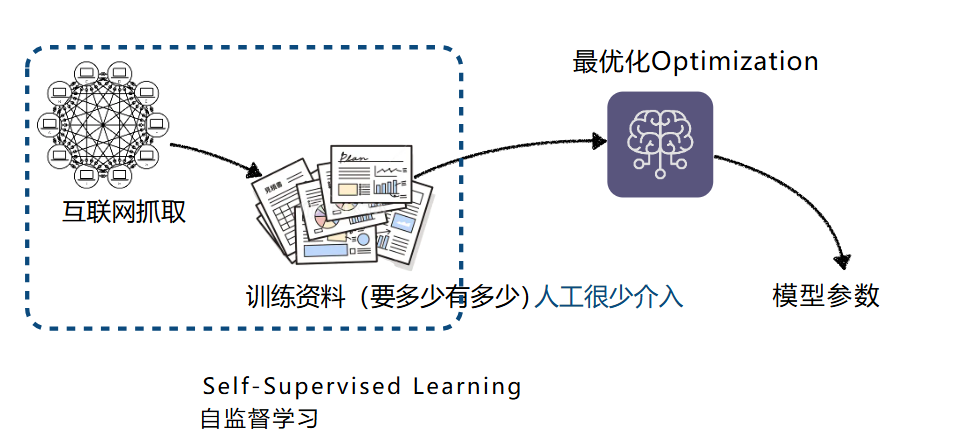
- 今天收集资料也许没有那么复杂,互联网上有无穷无尽的资料
- 这种只需要非常少的人工介入就可以取得训练资料的学习方式,叫自监督学习。语言模型不需要人工介入,只要不断的抓数据就可以训练模型
- Deep mind《扩展语言模型:训练 Gopher 的方法、分析和见解》
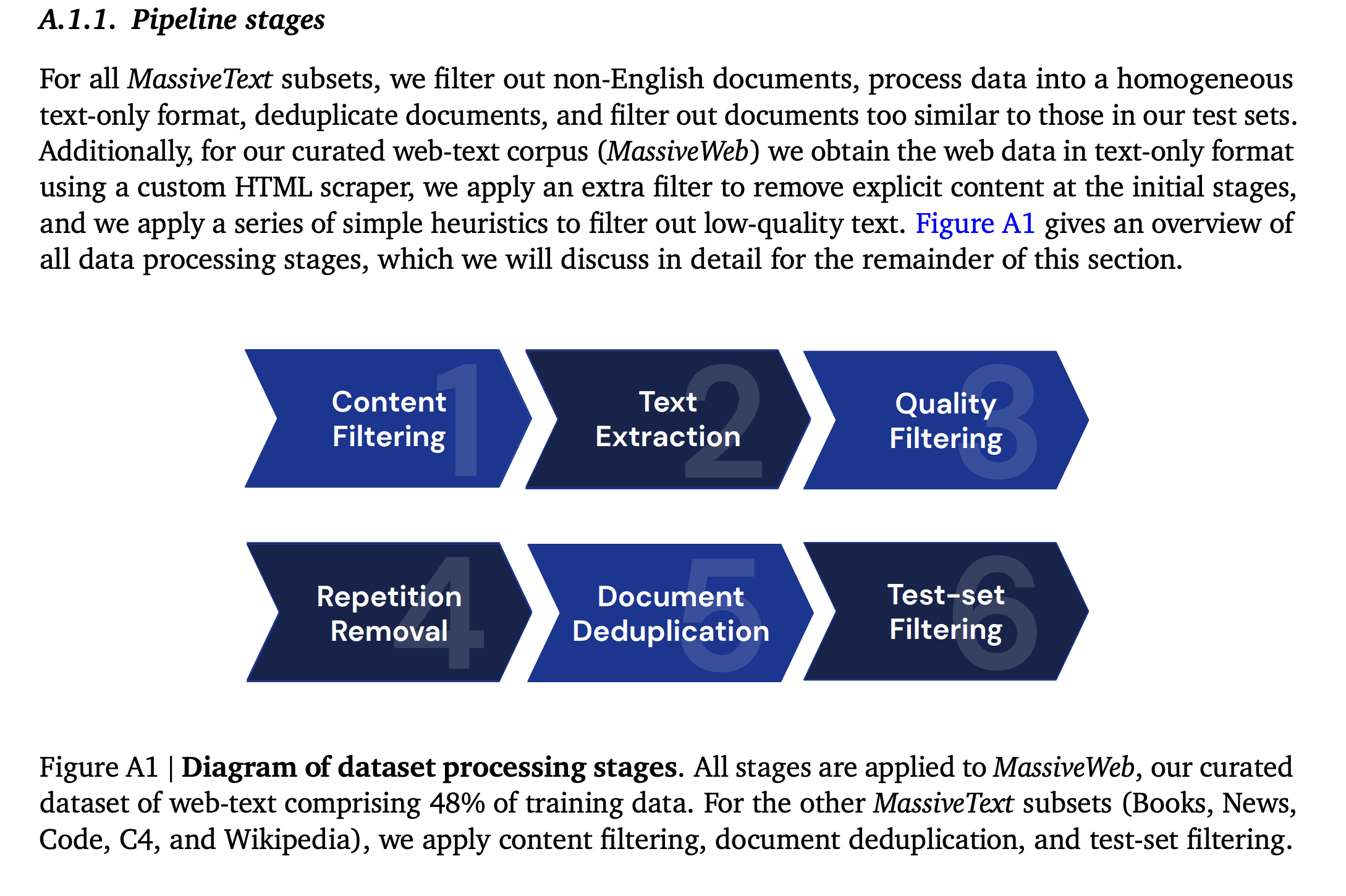
· 过滤有害内容如涩情 |
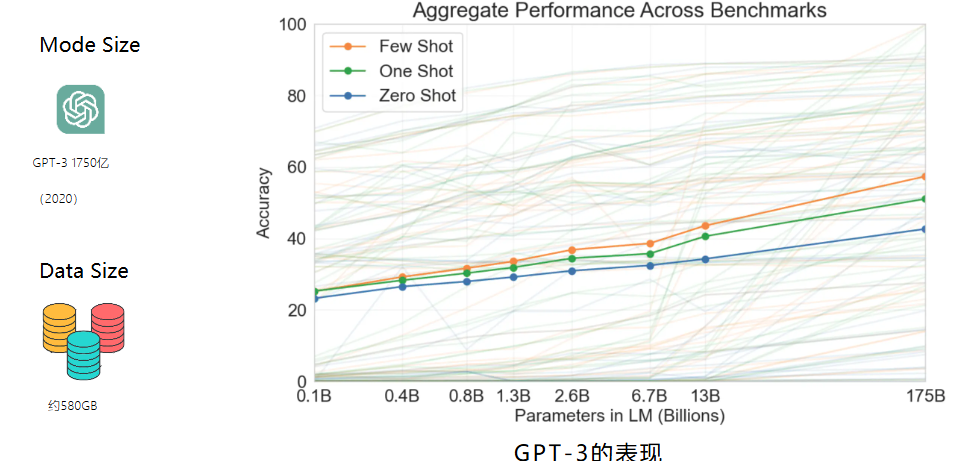
- GPT2没有好的表现咋搞,openai没有放弃,继续大力出奇迹,也许是模型不够大,gpt3是gpt2的100倍,大约3000亿和token
监督微调 SFT,Supervised Fine Tuning

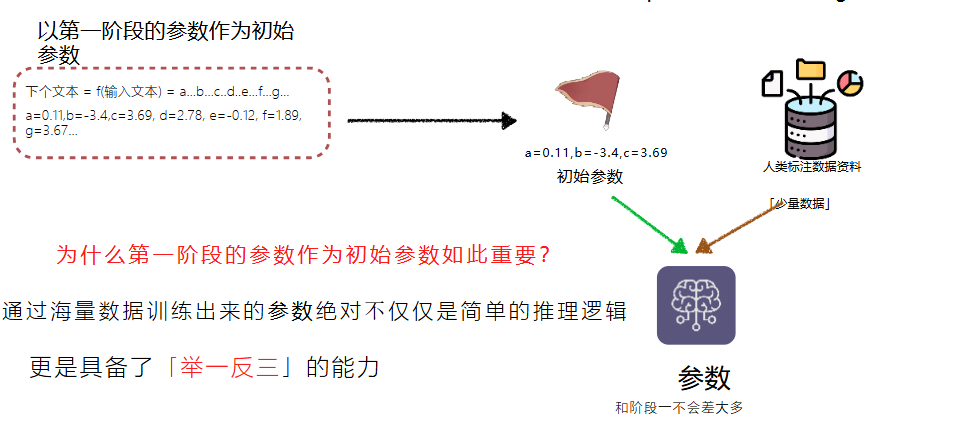
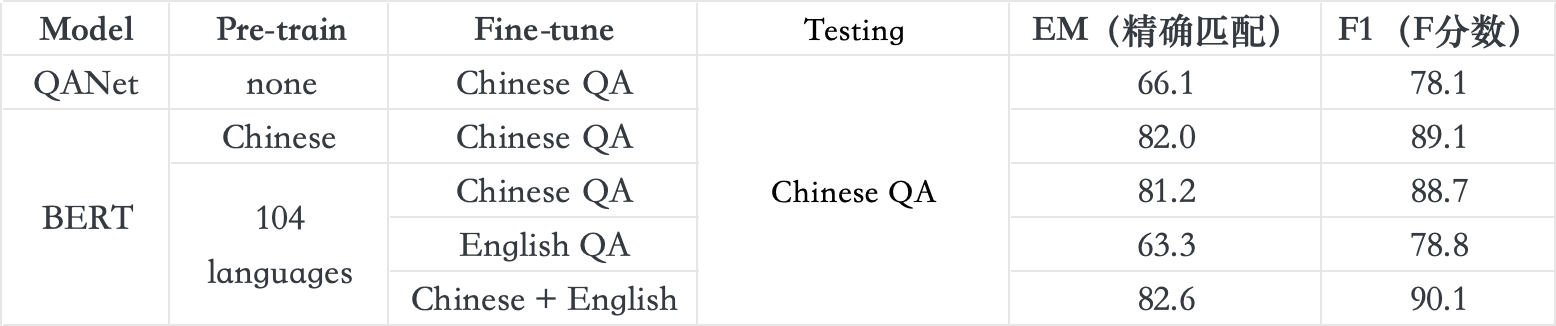
- Fine-tuning是否可以个人训练?可以
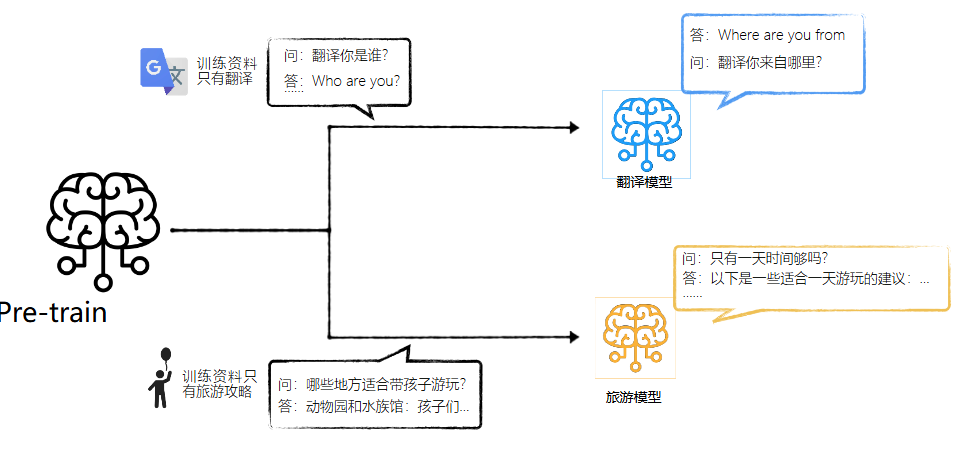

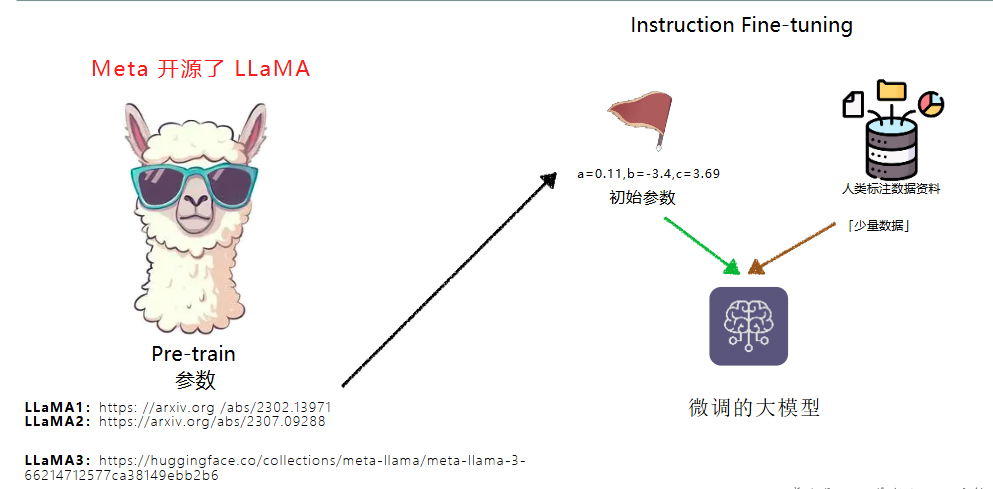
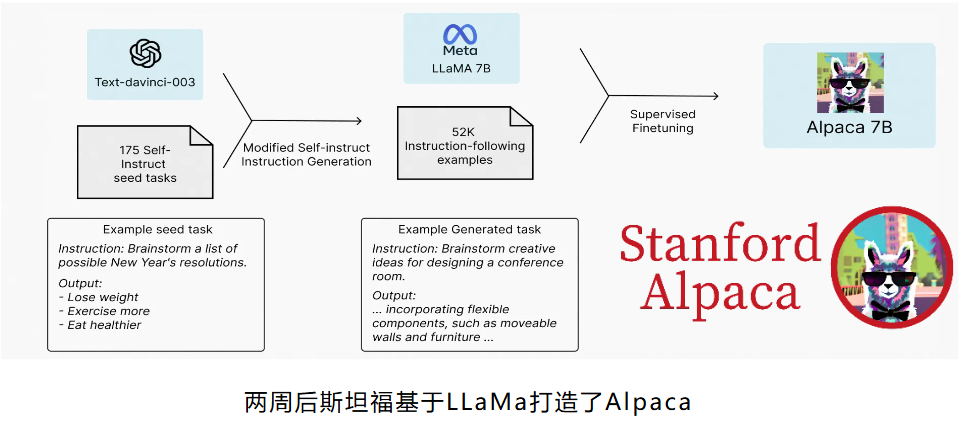
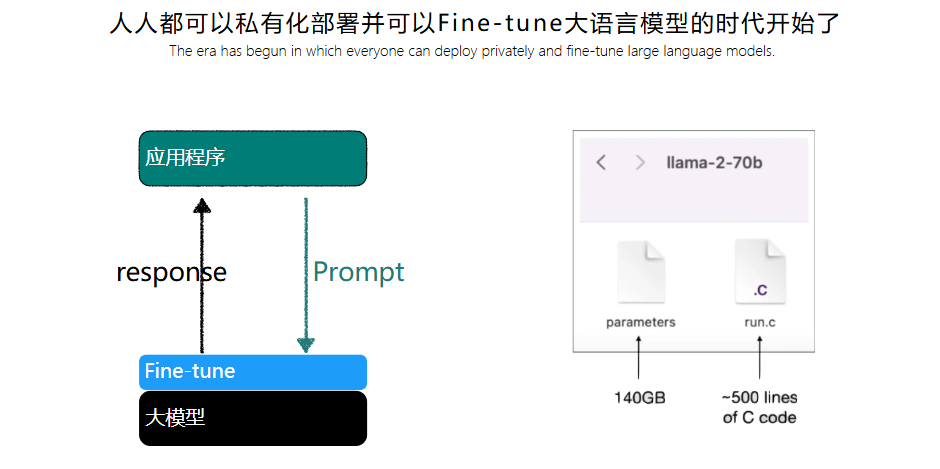
基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback )